How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021 скачать в хорошем качестве
How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021 в качестве 4k
У нас вы можете посмотреть бесплатно How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How to quickly build Data Pipelines for Data Scientists - Geert Jongen | PyData Eindhoven 2021
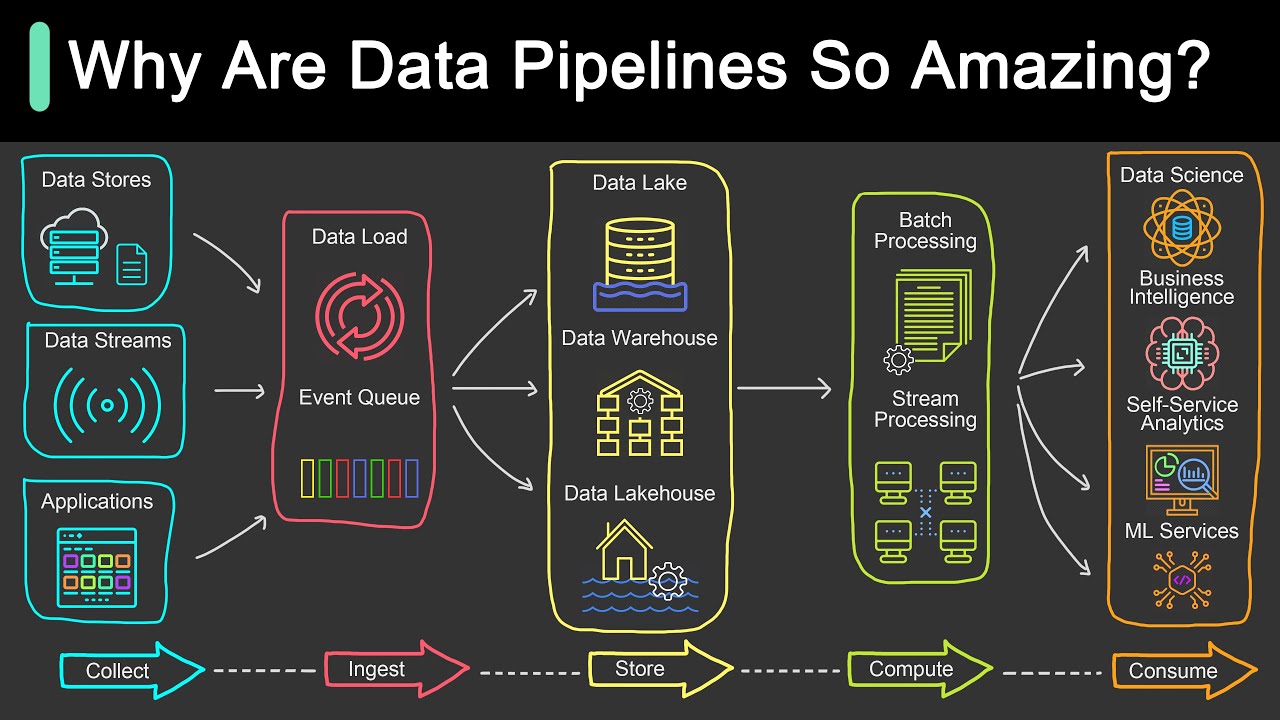
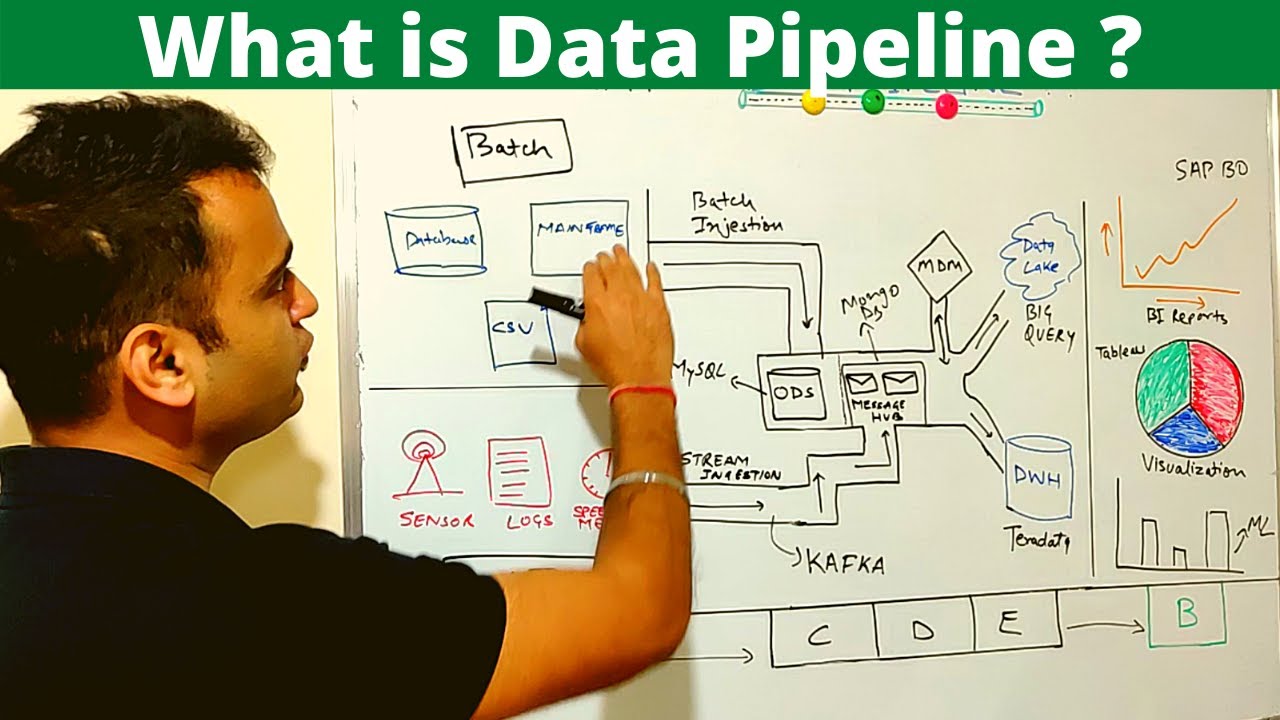
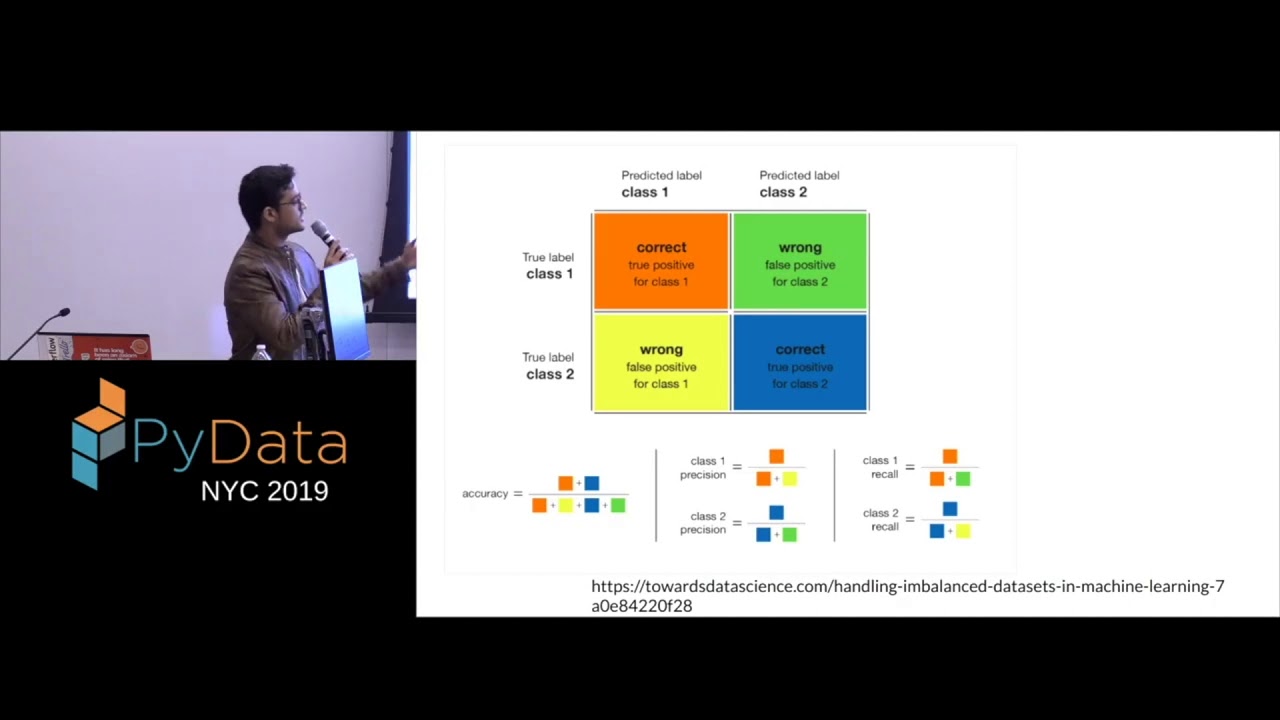
Data pipelines usually consist of loading the data, transforming it and writing to some other location. Initially, this does not sound very complicated. The question arises why it is so hard then to do? In this talk we will discuss how to perform these steps in pyspark, and especially what the latest developments are around delta lake, data quality checks and data modeling. What patterns are preferable and why? At the end of this talk data engineers and data scientists should have a view on a pattern that will fit in a lot of general situations and will help them to set up a pipeline more quickly while preventing a lot of issues upfront. Geert: is a data consultant working at Pipple, with extensive experience in the domain of data engineering, data science and software. Developing data platforms using cloud native technologies is what he enjoys most. Especially the messy process of bringing POCs into production is what he likes to do. GitHub: https://github.com/Jongen87/ Twitter: / jongen87 PyData Eindhoven 2021 Website: https://pydata.org/eindhoven2021/ Twitter: / pydataeindhoven === www.pydata.org PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R. PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases. 00:00 Introduction 01:58 Data Pipelines 07:32 Tip 1: Define a Clear Split Between Data Engineering and Data Science 08:58 Tip 2: For the Data Pipeline Part Use Notebooks in Flows 10:34 Tip 3: Have a Sit-Down With Your Team and Decide on Standards 11:14 Tip 4: All Data You Use Needs to Have a Source 12:36 Tip 5: Prepare for Changes 13:36 Delta Lake 16:38 Demo 26:50 Conclusion S/o to https://github.com/mraxilus for the video timestamps! Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVi...
Comments