Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks скачать в хорошем качестве
Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks в качестве 4k
У нас вы можете посмотреть бесплатно Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Towards Building a Heavy-Tailed Theory of Stochastic Gradient Descent for Deep Neural Networks
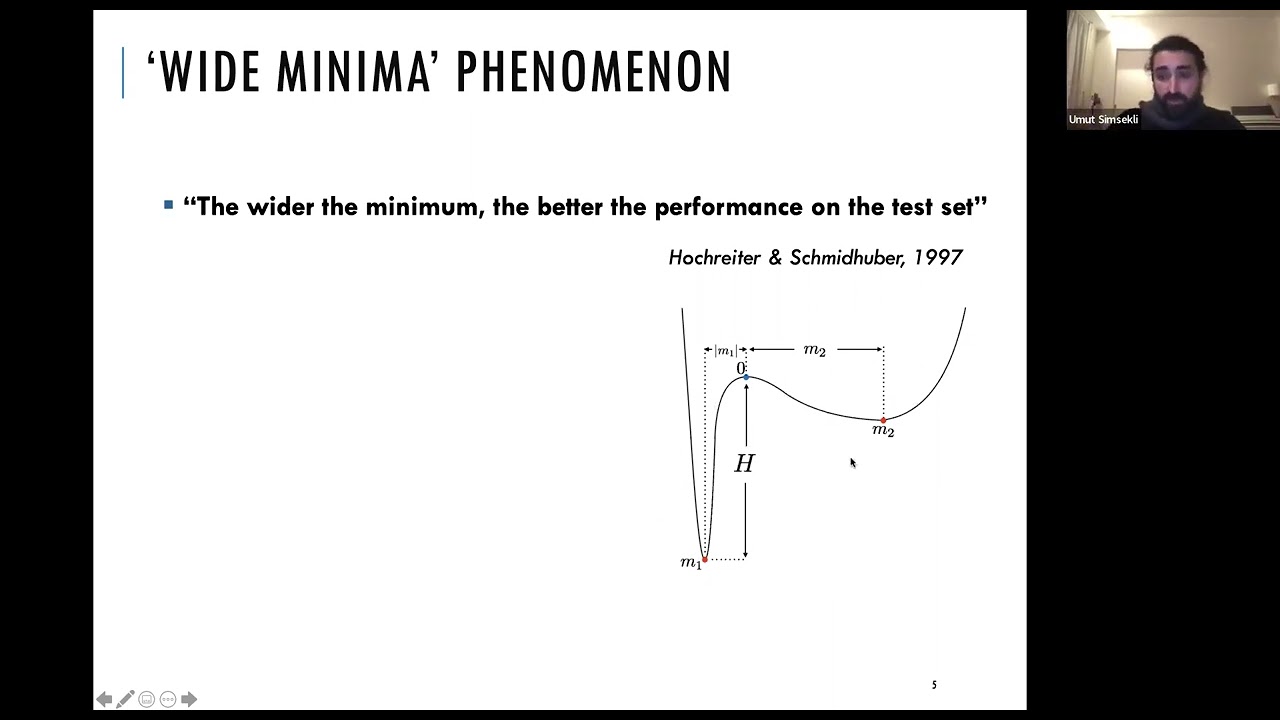
Abstract: In this talk, I will focus on the 'tail behavior' of SGD in deep learning. I will first empirically illustrate that heavy tails arise in the gradient noise (i.e., the difference between the stochastic gradient and the true gradient). Accordingly, I will propose to model the gradient noise as a heavy-tailed α-stable random vector and accordingly propose to analyze SGD as a discretization of a stochastic differential equation (SDE) driven by a stable process. As opposed to classical SDEs that are driven by a Brownian motion, SDEs driven by stable processes can incur ‘jumps’, which force the SDE (and its discretization) transition from 'narrow minima' to 'wider minima', as proven by existing metastability theory and the extensions that we proved recently. These results open up a different perspective and shed more light on the view that SGD 'prefers' wide minima. In the second part of the talk, I will focus on the generalization properties of such heavy-tailed SDEs and show that the generalization error can be controlled by the Hausdorff dimension of the trajectories of the SDE, which is closely linked to the tail behavior of the driving process. Our results imply that heavier-tailed processes should achieve better generalization; hence, the tail-index of the process can be used as a notion of "capacity metric”. Finally, if time permits, I will talk about the 'originating cause' of such heavy-tailed behavior and present theoretical results which show that heavy-tails can even emerge in very sterile settings such as linear regression with i.i.d Gaussian data. Speaker Bio: Umut Şimşekli is a tenured Research Faculty at Inria Paris and Ecole Normale Superieure de Paris. He received his Ph.D. degree in 2015 from Bogaziçi University, İstanbul. During 2016-2020, he was affiliated with the Signals, Statistics, and Machine Learning Group at Telecom Paris as an associate professor and he visited the University of Oxford, Department of Statistics during the 2019-2020 academic year. He is a laureate of the European Research Council (ERC) Starting Grant 2021 and his current research interests are in the theory of deep learning.
Comments



















