Actor Critic Methods Foundations скачать в хорошем качестве
Actor Critic Methods Foundations
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Actor Critic Methods Foundations в качестве 4k
У нас вы можете посмотреть бесплатно Actor Critic Methods Foundations или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Actor Critic Methods Foundations в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Actor Critic Methods Foundations
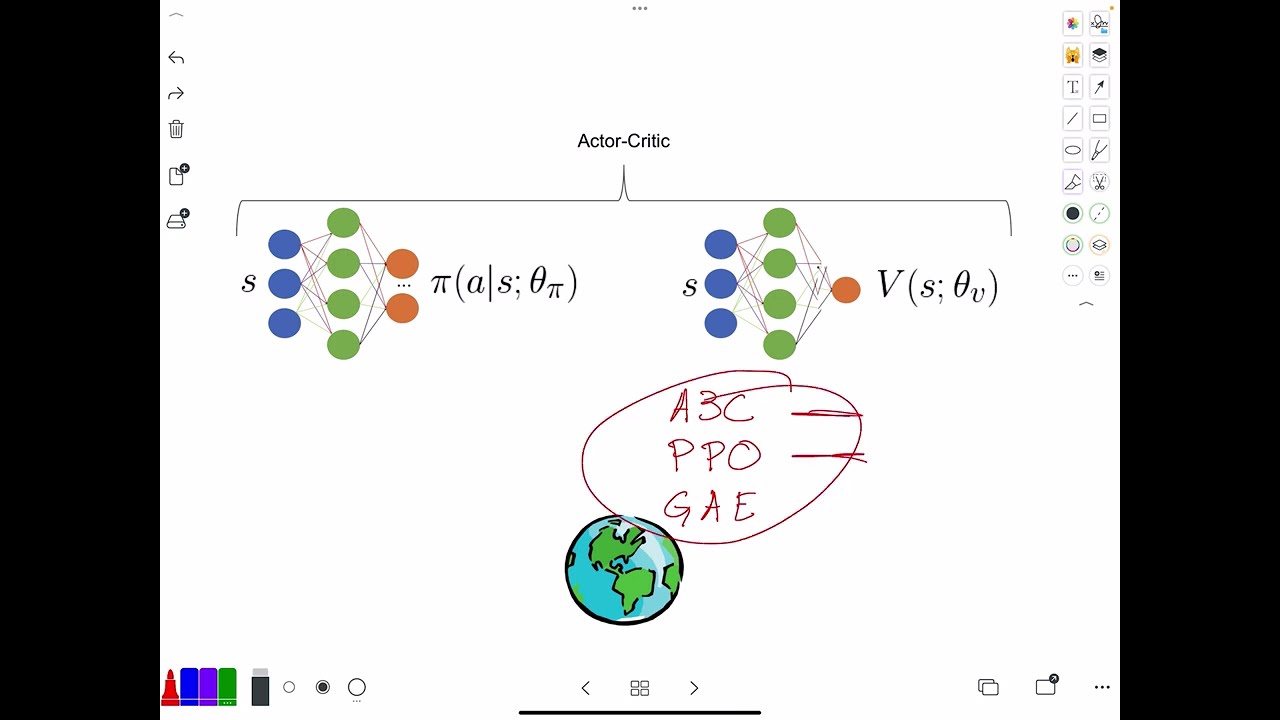
The speaker explains how to estimate returns in reinforcement learning, with a focus on the actor-critic architecture. In the Monte Carlo return method, the learning process involves playing a series of matches, reflecting on the outcomes, and adjusting behavior to increase the likelihood of winning in the future. This method has high variance because good actions might be overlooked if the overall match is lost. The actor-critic architecture consists of an actor, which makes decisions based on the current state, and a critic, which evaluates the decision and provides feedback. In this architecture, the actor is represented by a neural network that takes in the state of the environment and outputs an action, while the critic is represented by a value function that estimates the expected return based on the current state. The speaker then explains the actor-critic algorithm, where the environment outputs an observation, the policy network outputs an action based on that observation, and the environment responds by evolving and providing a new observation and reward. These experiences are used to train the value function (critic), which then helps calculate the advantage function used to train the policy network (actor). The speaker recommends three papers for further reading: A3C, PPO, and Generalized Advantage Estimation. These papers will help the audience understand the implementation of actor-critic methods. Papers mentioned: https://docs.google.com/spreadsheets/...
Comments