GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model. скачать в хорошем качестве
GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model.
5 часов назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
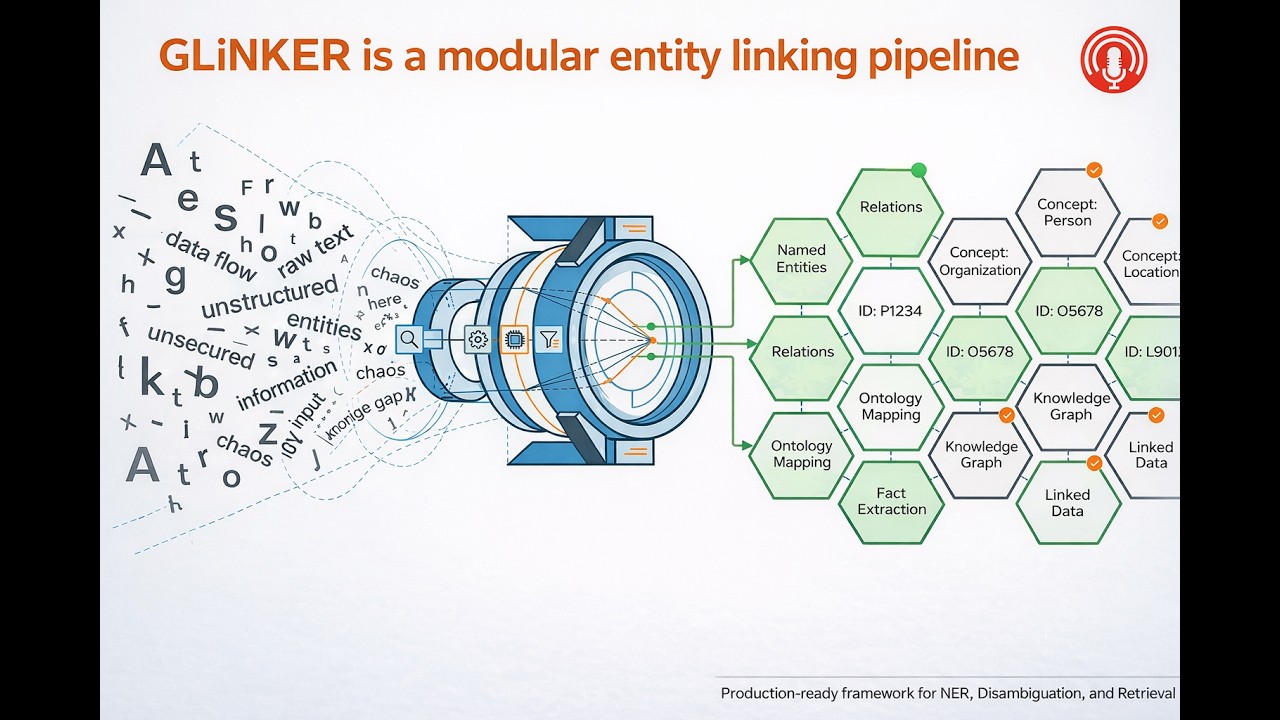
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model. в качестве 4k
У нас вы можете посмотреть бесплатно GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model. или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model. в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
GLiNKER - Entity Linking Framework + GLiNER - The Generalist Information Extraction Model.
GLiNKER and GLiNER - the next evolution in entity linking. Information is everywhere, but structure? That’s the hard part. For years, we’ve been stuck between a rock and a hard place. On one side, you have classical deep learning—accurate, sure, but rigid as a board and hungry for massive datasets. On the other side, we have the giants: Large Language Models. They’re brilliant generalists, but let's be real—they’re expensive, they’re slow, and getting them to spit out consistently structured data is like herding cats. But what if you could have the brain of a generalist in the body of a lightweight encoder? Today, we’re diving into a breakthrough paper by Ihor Stepanov and Mykhailo Shtopko: 'GLiNER multi-task: Generalist Lightweight Model for Various Information Extraction Tasks.' We’re talking about a model that doesn’t just keep up; it sets the pace. From hitting State-of-the-Art performance on zero-shot NER benchmarks to tackling QA, summarization, and relation extraction—all without the LLM price tag. But we aren't just talking theory. We’re also looking at GLiNKER—a production-ready, modular entity-linking pipeline that takes GLiNER’s raw power and plugs it into a high-performance stack involving Redis, Elasticsearch, and PostgreSQL. Whether you're switching from mapping biomedical genes to scanning legal contracts just by changing a few strings, or you're looking to simplify your inference stack with a unified architecture, this episode is your blueprint. Let’s get into how GLiNER is redefining what 'lightweight' can really do. Key Highlights we'll cover: The Zero-Shot Superpower: How to identify any entity type without a single drop of fine-tuning data. The Multi-Task Edge: Why a single encoder is beating out the heavyweights in relation extraction and QA. Production-Ready Pipelines: A deep dive into GLiNKER’s DAG-based execution and multi-layer caching. Self-Learning NER: How GLiNER models are teaching themselves to be even more accurate.
Comments
-
 4 месяца назад
4 месяца назад
-
 1 месяц назад
1 месяц назад
-
 Трансляция закончилась 11 дней назад
Трансляция закончилась 11 дней назад
-
 2 месяца назад
2 месяца назад
-
 1 месяц назад
1 месяц назад
-
![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg) 1 месяц назад
1 месяц назад
-
 3 дня назад
3 дня назад
-
 1 месяц назад
1 месяц назад
-
 2 месяца назад
2 месяца назад
-
 4 месяца назад
4 месяца назад
-
 2 месяца назад
2 месяца назад
-
 2 дня назад
2 дня назад
-
 3 недели назад
3 недели назад
-
 1 год назад
1 год назад
-
 2 года назад
2 года назад
-
 2 недели назад
2 недели назад
-
 1 месяц назад
1 месяц назад
-
 3 года назад
3 года назад
-
![[TIMM] PyTorch Image Models. Structural Evolution of Vision and Video Architectures in the PyTorch](https://imager.clipsaver.ru/6TzDm9fJ2Bg/max.jpg) 4 часа назад
4 часа назад
-
 11 дней назад
11 дней назад