śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B —Ā–ļ–į—á–į—ā—Ć –≤ —Ö–ĺ—Ä–ĺ—ą–Ķ–ľ –ļ–į—á–Ķ—Ā—ā–≤–Ķ
śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B
5 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
–Ě–Ķ —É–ī–į–Ķ—ā—Ā—Ź –∑–į–≥—Ä—É–∑–ł—ā—Ć Youtube-–Ņ–Ľ–Ķ–Ķ—Ä. –ü—Ä–ĺ–≤–Ķ—Ä—Ć—ā–Ķ –Ī–Ľ–ĺ–ļ–ł—Ä–ĺ–≤–ļ—É Youtube –≤ –≤–į—ą–Ķ–Ļ —Ā–Ķ—ā–ł.
–ü–ĺ–≤—ā–ĺ—Ä—Ź–Ķ–ľ –Ņ–ĺ–Ņ—č—ā–ļ—É...
–ü–ĺ–≤—ā–ĺ—Ä—Ź–Ķ–ľ –Ņ–ĺ–Ņ—č—ā–ļ—É...
–°–ļ–į—á–į—ā—Ć –≤–ł–ī–Ķ–ĺ —Ā —é—ā—É–Ī –Ņ–ĺ —Ā—Ā—č–Ľ–ļ–Ķ –ł–Ľ–ł —Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –Ī–Ķ–∑ –Ī–Ľ–ĺ–ļ–ł—Ä–ĺ–≤–ĺ–ļ –Ĺ–į —Ā–į–Ļ—ā–Ķ: śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B –≤ –ļ–į—á–Ķ—Ā—ā–≤–Ķ 4k
–£ –Ĺ–į—Ā –≤—č –ľ–ĺ–∂–Ķ—ā–Ķ –Ņ–ĺ—Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –Ī–Ķ—Ā–Ņ–Ľ–į—ā–Ĺ–ĺ śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B –ł–Ľ–ł —Ā–ļ–į—á–į—ā—Ć –≤ –ľ–į–ļ—Ā–ł–ľ–į–Ľ—Ć–Ĺ–ĺ–ľ –ī–ĺ—Ā—ā—É–Ņ–Ĺ–ĺ–ľ –ļ–į—á–Ķ—Ā—ā–≤–Ķ, –≤–ł–ī–Ķ–ĺ –ļ–ĺ—ā–ĺ—Ä–ĺ–Ķ –Ī—č–Ľ–ĺ –∑–į–≥—Ä—É–∂–Ķ–Ĺ–ĺ –Ĺ–į —é—ā—É–Ī. –Ē–Ľ—Ź –∑–į–≥—Ä—É–∑–ļ–ł –≤—č–Ī–Ķ—Ä–ł—ā–Ķ –≤–į—Ä–ł–į–Ĺ—ā –ł–∑ —Ą–ĺ—Ä–ľ—č –Ĺ–ł–∂–Ķ:
-
–ė–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—Ź –Ņ–ĺ –∑–į–≥—Ä—É–∑–ļ–Ķ:
–°–ļ–į—á–į—ā—Ć mp3 —Ā —é—ā—É–Ī–į –ĺ—ā–ī–Ķ–Ľ—Ć–Ĺ—č–ľ —Ą–į–Ļ–Ľ–ĺ–ľ. –Ď–Ķ—Ā–Ņ–Ľ–į—ā–Ĺ—č–Ļ —Ä–ł–Ĺ–≥—ā–ĺ–Ĺ śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B –≤ —Ą–ĺ—Ä–ľ–į—ā–Ķ MP3:
–ē—Ā–Ľ–ł –ļ–Ĺ–ĺ–Ņ–ļ–ł —Ā–ļ–į—á–ł–≤–į–Ĺ–ł—Ź –Ĺ–Ķ
–∑–į–≥—Ä—É–∑–ł–Ľ–ł—Ā—Ć
–Ě–ź–Ė–ú–ė–Ę–ē –ó–Ē–ē–°–¨ –ł–Ľ–ł –ĺ–Ī–Ĺ–ĺ–≤–ł—ā–Ķ —Ā—ā—Ä–į–Ĺ–ł—Ü—É
–ē—Ā–Ľ–ł –≤–ĺ–∑–Ĺ–ł–ļ–į—é—ā –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā–ĺ —Ā–ļ–į—á–ł–≤–į–Ĺ–ł–Ķ–ľ –≤–ł–ī–Ķ–ĺ, –Ņ–ĺ–∂–į–Ľ—É–Ļ—Ā—ā–į –Ĺ–į–Ņ–ł—ą–ł—ā–Ķ –≤ –Ņ–ĺ–ī–ī–Ķ—Ä–∂–ļ—É –Ņ–ĺ –į–ī—Ä–Ķ—Ā—É –≤–Ĺ–ł–∑—É
—Ā—ā—Ä–į–Ĺ–ł—Ü—č.
–°–Ņ–į—Ā–ł–Ī–ĺ –∑–į –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ —Ā–Ķ—Ä–≤–ł—Ā–į ClipSaver.ru
śĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ÄźPaper&Hacks #68„ÄϜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B
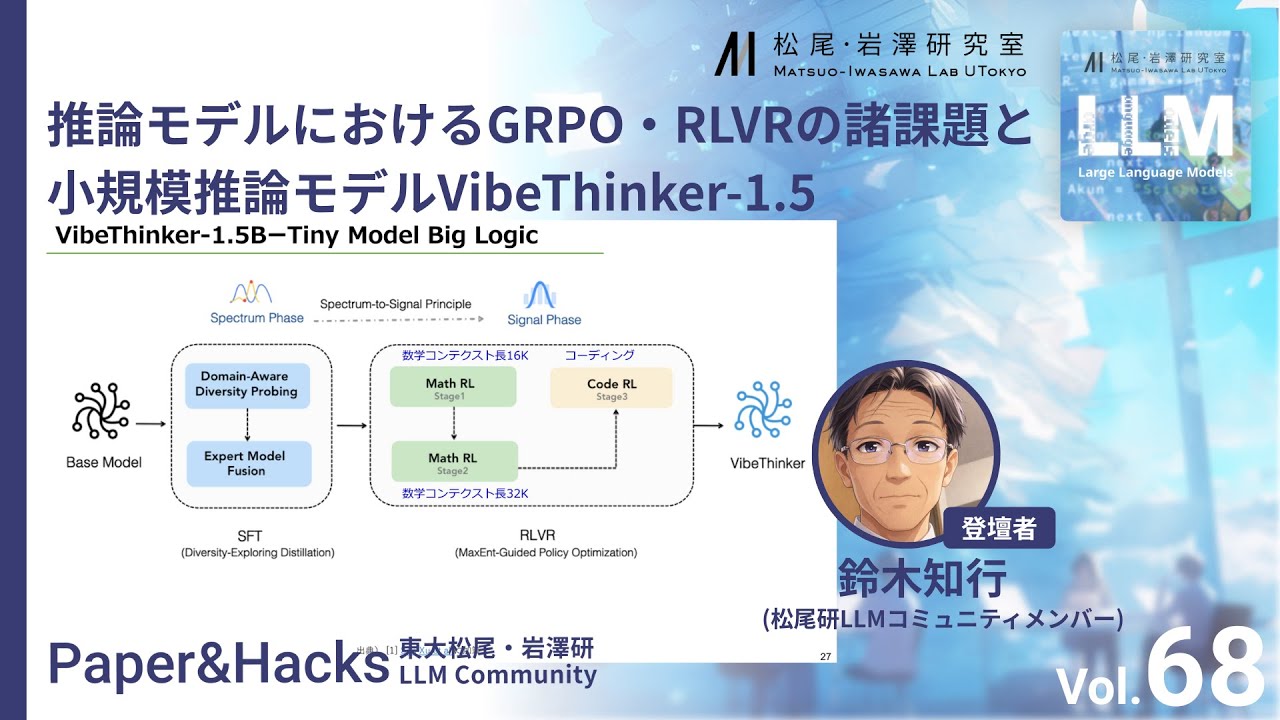
ś¶āŤ¶Ā: śĮéťÄĪÁĀęśõúśó•20śôā„Āč„āČ„ÄĀśĚĺŚįĺ„ÉĽŚ≤©śĺ§Á†ĒÁ©∂Śģ§„ĀĆšłĽŚā¨„Āô„āčLLM„ĀęťĖĘ„Āô„ā荾™Ť™≠šľö & ŚģüŤ£Ö„Āģ„ā™„É≥„É©„ā§„É≥„ā§„Éô„É≥„Éą„Āß„Āô„Äā ŚĮĺŤĪ°: śôģśģĶ„Āč„āČŤęĖśĖá„ā퍙≠„āď„Āß„ĀĄ„āč/śôģśģĶ„Āč„āČLLM„ĀģŚģüŤ£Ö„ā퍰ƄĀ™„Ā£„Ā¶„ĀĄ„āčśĖĻ„ÄÖ „ɨ„Éô„Éę: ‚ėÖ‚ėÖ‚ėÖ‚ėÖ‚ėÜ„ÄÄ(Expert) ÁôļŤ°®ŤÄÖ: ťąīśú®Áü•Ť°ĆÔľąśĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„É°„É≥„Éź„ÉľÔľČ „āŅ„ā§„Éą„Éę: „ÄƜ鮍ęĖ„ÉĘ„Éá„Éę„Āę„Āä„ĀĎ„āčGRPO„ÉĽRLVR„ĀģŤęłŤ™≤ť°Ć„Ā®ŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„ÉęVibeThinker-1.5B„Äć ÁôļŤ°®„āę„ÉÜ„āī„É™: ÁźÜŤęĖšł≠ŚŅÉ „ā§„Éô„É≥„ÉąŚÜÖŚģĻ: ‚φRL„ĀĮŚüļÁõ§„ÉĘ„Éá„Éę„āíÁúü„ĀęŤ∂Ö„Āą„Ā¶„ĀĄ„āč„Āģ„ĀčÔľü ‚Ď°GRPO„Āę„Āä„ĀĎ„āč„ā®„É≥„Éą„É≠„ÉĒ„ÉľŚī©Ś£ä„ÉĽ„ÉĘ„Éá„ÉęŚī©Ś£ä„Ā®Ťß£śĪļÁ≠Ė ‚ĎĘŚįŹŤ¶Źś®°śé®ŤęĖ„ÉĘ„Éá„Éę„ĀĮŚŹĮŤÉĹ„Ā™„Āģ„ĀčÔľü ŤęĖśĖá„É™„É≥„āĮÔľö [1] Sen Xu et al. (2025) ‚ÄúTiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B‚ÄĚ arXiv:2511.06221 [2] Yang Yue et al. (2025) ‚ÄúDoes Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?‚ÄĚ arXiv:2504.13837 [3] Xumeng Wen et al. (2025) ‚ÄúRLVR CoT-PassKÔľöReinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs‚ÄĚ arXiv:2506.14245 [4] Qiying Yu et al. (2025) ‚ÄúDAPO: An Open-Source LLM Reinforcement Learning System at Scale ‚ÄĚ arXiv:2503.14476 [5] Chujie Zheng et al. (2025) ‚ÄúGroup Sequence Policy Optimization‚ÄĚ arXiv:2507.18071 [6] Mingjie Liu et al. (2025) ‚ÄúProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models‚ÄĚ arXiv:2505.24864 ----- „ĀĚ„ĀģšĽĖ ś¨°Śõě Paper & Hacks Ť¶ĖŤĀīÁĒ≥„ĀóŤĺľ„ĀŅ šĽäŚĺĆ„ĀģPaper & Hacks „ĀģÁôĽŚ£áÁĒ≥„ĀóŤĺľ„ĀŅ https://linktr.ee/matsuolab_community ś¨°Śõ써õŚļßÁĒ≥Ťĺľ„Éē„ā©„Éľ„Ɇ„ĀģŚÖ¨ťĖč„Āó„Ā¶„Āä„āä„Āĺ„Āô„Äā[šļąÁīĄ„Éē„ā©„Éľ„Ɇ„ĀĮ„Āď„Ā°„āČ](https://forms.gle/8GTirmvUH3KKRmXq5) ----- śú¨ÁôļŤ°®„ĀĮ„ÄĀśĚĺŚįĺÁ†ĒLLM„ā≥„Éü„É•„Éč„ÉÜ„ā£„ĀꌏāŚä†„Āó„Ā¶„ĀĄ„āč„É°„É≥„Éź„ÉľŚÄčšļļ„ĀģŤ¶čŤß£„ĀęŚüļ„Ā•„ĀŹ„āā„Āģ„Āß„Āā„āä„ÄĀśĚĪšļ¨Ś§ßŚ≠¶„Ā™„āČ„Ā≥„ĀęśĚĺŚįĺ„ÉĽŚ≤©śĺ§Á†ĒÁ©∂Śģ§Á≠Č„ĀģÁĶĄÁĻĒ„ā횼£Ť°®„Āô„āč„āā„Āģ„Āß„ĀĮ„Āā„āä„Āĺ„Āõ„āď„Äā
Comments
-
 1 –≥–ĺ–ī –Ĺ–į–∑–į–ī
1 –≥–ĺ–ī –Ĺ–į–∑–į–ī
-

-
 4 –≥–ĺ–ī–į –Ĺ–į–∑–į–ī
4 –≥–ĺ–ī–į –Ĺ–į–∑–į–ī
-
 11 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
11 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
-
 2 –Ĺ–Ķ–ī–Ķ–Ľ–ł –Ĺ–į–∑–į–ī
2 –Ĺ–Ķ–ī–Ķ–Ľ–ł –Ĺ–į–∑–į–ī
-
 11 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
11 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
-
 7 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
7 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
-
 18 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
18 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
-
 1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
-
 4 –ľ–Ķ—Ā—Ź—Ü–į –Ĺ–į–∑–į–ī
4 –ľ–Ķ—Ā—Ź—Ü–į –Ĺ–į–∑–į–ī
-
 5 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
5 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
-
 3 –ľ–Ķ—Ā—Ź—Ü–į –Ĺ–į–∑–į–ī
3 –ľ–Ķ—Ā—Ź—Ü–į –Ĺ–į–∑–į–ī
-
 5 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
5 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
-
![–ö–į–ļ –≤–Ĺ–ł–ľ–į–Ĺ–ł–Ķ —Ā—ā–į–Ľ–ĺ –Ĺ–į—Ā—ā–ĺ–Ľ—Ć–ļ–ĺ —ć—Ą—Ą–Ķ–ļ—ā–ł–≤–Ĺ—č–ľ [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg) 1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
-
 6 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
6 –ī–Ĺ–Ķ–Ļ –Ĺ–į–∑–į–ī
-
 13 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
13 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
-
 5 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
5 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
-
 2 –≥–ĺ–ī–į –Ĺ–į–∑–į–ī
2 –≥–ĺ–ī–į –Ĺ–į–∑–į–ī
-
 1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
1 –ľ–Ķ—Ā—Ź—Ü –Ĺ–į–∑–į–ī
-
 18 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī
18 —á–į—Ā–ĺ–≤ –Ĺ–į–∑–į–ī