Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP скачать в хорошем качестве
Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP
1 месяц назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP в качестве 4k
У нас вы можете посмотреть бесплатно Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Transformer Architecture in Tamil | Encoder Decoder & Attention Explained | Deep Learning NLP
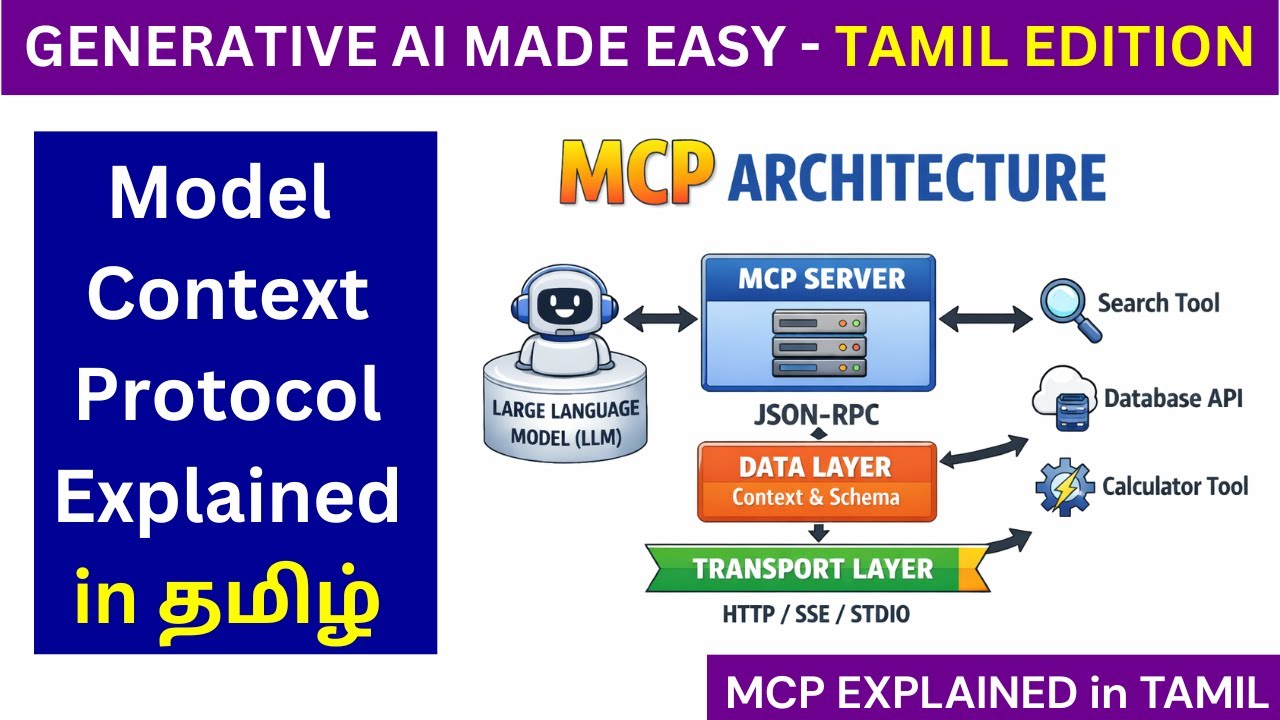
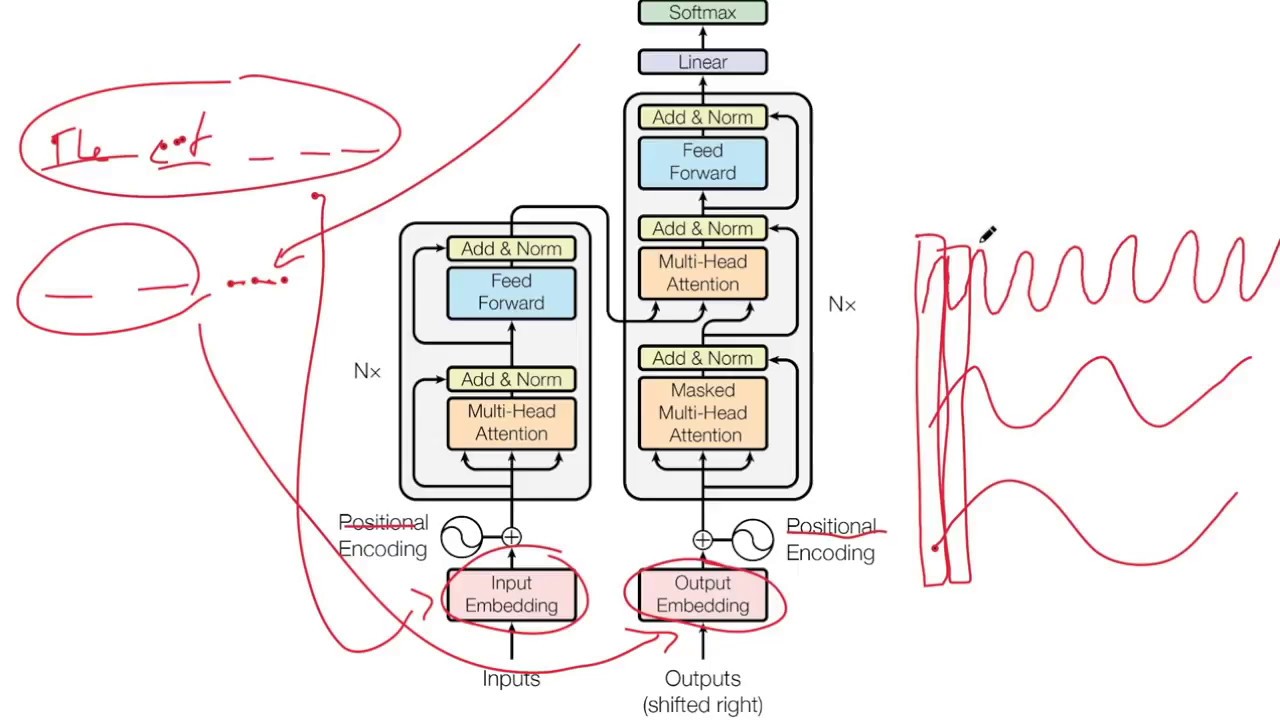
In this video, we dive deep into Transformer Architecture explained in Tamil, one of the most important and widely used architectures in Deep Learning, NLP, and Generative AI today. This video is a part of our Deep Learning Full Series in Tamil, designed specifically for learners who want to understand complex AI concepts in a simple, intuitive, and practical way using Tamil language. If you are a college student preparing for placements, a working professional upskilling in AI, or someone curious about how modern models like ChatGPT, Google Translate, and BERT work internally, this video is made for you. This video explains the Transformer model step by step, without skipping fundamentals. Instead of memorizing formulas, we focus on why each component exists and how it works internally. To make the concept crystal clear, we explain the entire transformer architecture using a real-world example of English to Tamil sentence translation. By the end of this video, you will clearly understand how a sentence is taken as input, processed through the encoder and decoder, and finally converted into a meaningful Tamil translation. We start with the input embeddings, explaining how words are converted into vectors and why embeddings are necessary for neural networks. Then we move into positional encoding, where you’ll understand how transformers capture word order without using RNNs or LSTMs. From there, we explain self-attention in Tamil, showing how each word attends to other words in the sentence and why attention is the heart of the transformer architecture. Next, we break down multi-head attention, explaining why multiple attention heads are used instead of just one and how they help the model learn different relationships like grammar, meaning, and context at the same time. We then explain residual connections and layer normalization, clarifying how they help with stable training, faster convergence, and solving vanishing or exploding gradient problems in deep neural networks. After covering the encoder architecture in detail, we move to the decoder side of the transformer. Here, we explain masked multi-head attention, showing why masking is required during training and how it prevents the model from cheating by looking at future words. We then explain cross attention (encoder-decoder attention) in a very intuitive way, showing how the decoder focuses on relevant parts of the English sentence while generating the Tamil output. We also explain the role of Feed Forward Neural Networks (FFNN) inside transformers, why they exist after attention layers, and how they help in feature transformation. Finally, we cover output embeddings, linear layers, and softmax, explaining how the final probability distribution over Tamil words is generated and how the best word is chosen at each step during translation. This video is especially useful for learners who feel that most AI content is only available in English or explained in a very abstract way. Our goal is to make Deep Learning in Tamil easy, practical, and confidence-building. You don’t need advanced math knowledge to follow this video; concepts are explained visually, logically, and step by step. If you are learning Transformers, NLP, Deep Learning, Machine Learning, Generative AI, or preparing for interviews, this video will give you a strong conceptual foundation. Make sure to watch the video till the end, as each component builds on the previous one, just like how transformers work internally. If you found this explanation helpful, don’t forget to like, share, and subscribe to the channel for more AI, Deep Learning, Data Science, and Programming tutorials in Tamil. Stay tuned for upcoming videos in this Deep Learning series where we will cover advanced models, practical implementations, and real-world AI use cases in Tamil. #tamil #machinelearning #deeplearning #adiexplains #artificialintelligence #ai #transformers #naturallanguageprocessing #nlp #computerscience #programming #learning #deeplearningprojects #datascience #selfattention #agents #largelanguagemodels #llm
Comments