Data assimilation workflow for large models - Data Assimilation Research Testbed (DART) скачать в хорошем качестве
Data assimilation workflow for large models - Data Assimilation Research Testbed (DART)
8 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Data assimilation workflow for large models - Data Assimilation Research Testbed (DART) в качестве 4k
У нас вы можете посмотреть бесплатно Data assimilation workflow for large models - Data Assimilation Research Testbed (DART) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Data assimilation workflow for large models - Data Assimilation Research Testbed (DART) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Data assimilation workflow for large models - Data Assimilation Research Testbed (DART)
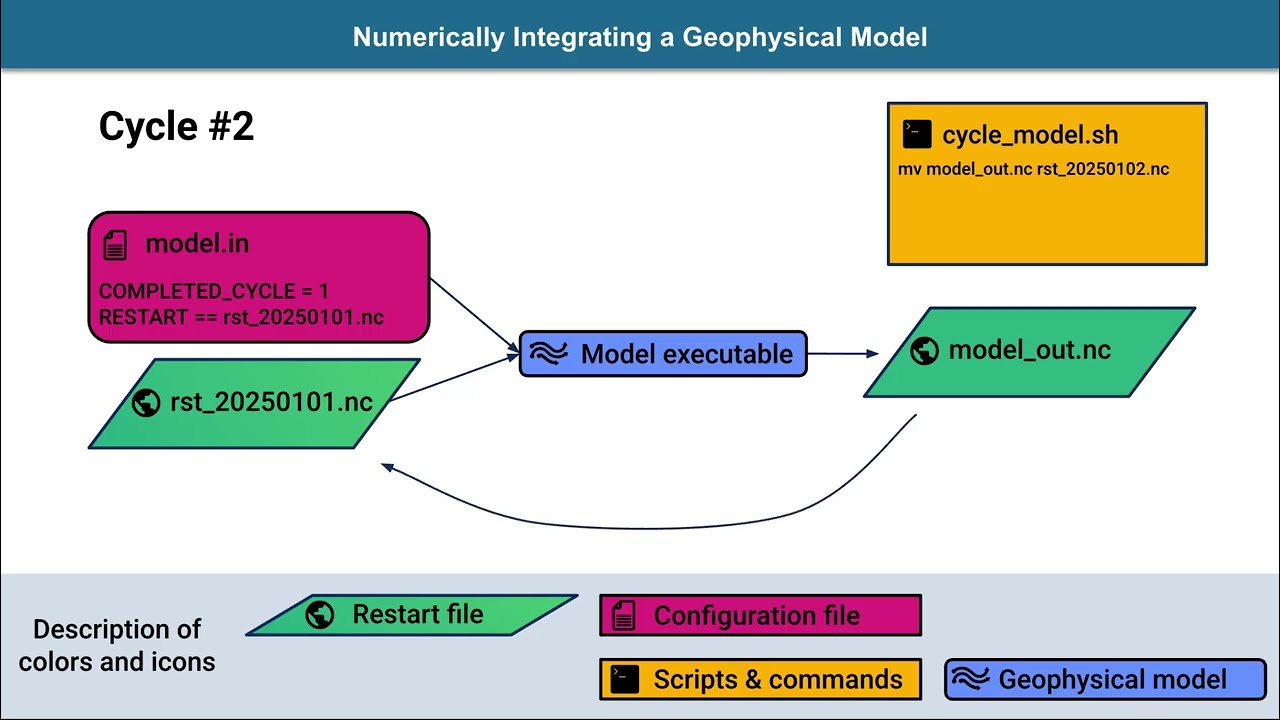
These slides depict a process you should already be familiar with: the numerical integration of a geophysical model. Then they continue by adding in just a couple of additional components to demonstrate how the data assimilation itself is implemented. So, to begin, when integrating a geophysical model, there are typically four components needed: the geophysical model executable, configuration or namelist files that are input to the model that control how the model is run, restart or initial conditions files that store the model state and scripts or commands that allocate computing resources to run the model and move files around the filesystem. Since a typical geophysical model needs more than one processor to run a batch script is submitted instructing the computing cluster to use MPI to run the model executable. A netCDF file is output containing the new model state and the batch job completes. A workflow script is invoked to change settings in configuration files and move data files around the filesystem. Certain modeling systems have intricate workflow scripts to handle these tasks for you. For example CESM and E3SM use the Common Infrastructure for Modeling the Earth or CIME scripts to handle workflow. In this example case, a simple cycle_model.sh script handles the workflow. It renames the model output with the date of the integration, year 2025, month 01, day 01. This newly output file is set as input for the next integration cycle by editing the configuration file to reflect that rst_20250101.nc should be used as the new restart file. The first cycle has been completed and a second cycle can progress much like the first. With the model.in file already configured appropriately, a batch job is submitted that runs an MPI job, the model integrates, and a new output file is created. The MPI job completes and another cycle_model script is run renaming the output file with the date of the integration: year 2025, month 01, day 01. The newly output file is set as the input file for the next integration by editing the model.in file to reflect that rst_20250102.nc should be used as the restart file for a subsequent integration. With these four components, we’re able to integrate a geophysical model. Adding two more components enables cycling with data assimilation: DART programs and observation files. Instead of using a single model restart file, DART uses an ensemble of model restart files. Starting again with our geophysical model, and additional executable, DART’s filter program, implements the data assimilation algorithm. DART has its own configuration file, named input.nml which contains many namelists. This selection from the filter namelist shows multiple restart files, rst_20250101 001, 002 and 003 .nc which are drawn using slightly different shades of green to reflect that the ensemble contains restart files with slightly different model states. The assimilation algorithm requires some spread in the ensemble in order for the data to be assimilated. Such a model ensemble can be created using the perturb_single_instance executable that can be compiled with the quickbuild script. A file containing the relevant observations on January 1st, 2025 is needed. It’s stored in an observation sequence file that specifies the value of the observation and its observational error variance. Observation sequence files can be created with programs known as observation converters. These files are input into filter and a batch job is submitted that runs filter using MPI. After the data has been assimilated, an ensemble of restart files is output by filter containing the new model states after the assimilation has been performed. And the filter job completes. Since there are an ensemble of restart files that need to be input into the geophysical model, this workflow now has multiple model.in files that reference each of the restart files. The model in and restart files are input to the geophysical model and batch jobs are submitted in turn for each ensemble member, outputting a new restart file after the integration completes. This process repeats for the second ensemble member and the third ensemble member. Then a workflow script is invoked to change settings in configuration files and move data files around the filesystem. The restart and observations files from the first cycle are archived and the input.nml file is edited to read in the newly created set of restart files. Thus, an entire cycle of data assimilation and model integration has been completed. This material is based upon work supported by the NSF National Center for Atmospheric Research, a major facility sponsored by the U.S. National Science Foundation and managed by the University Corporation for Atmospheric Research. Any opinions, findings and conclusions or recommendations expressed in this material do not necessarily reflect the views of the U.S. National Science Foundation.
Comments






![Как сжимаются изображения? [46 МБ ↘↘ 4,07 МБ] JPEG в деталях](https://imager.clipsaver.ru/Kv1Hiv3ox8I/max.jpg)