Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw скачать в хорошем качестве
Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw
8 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw в качестве 4k
У нас вы можете посмотреть бесплатно Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Big Data Processing with Apache Beam Python | SciPy 2017 | Robert Bradshaw
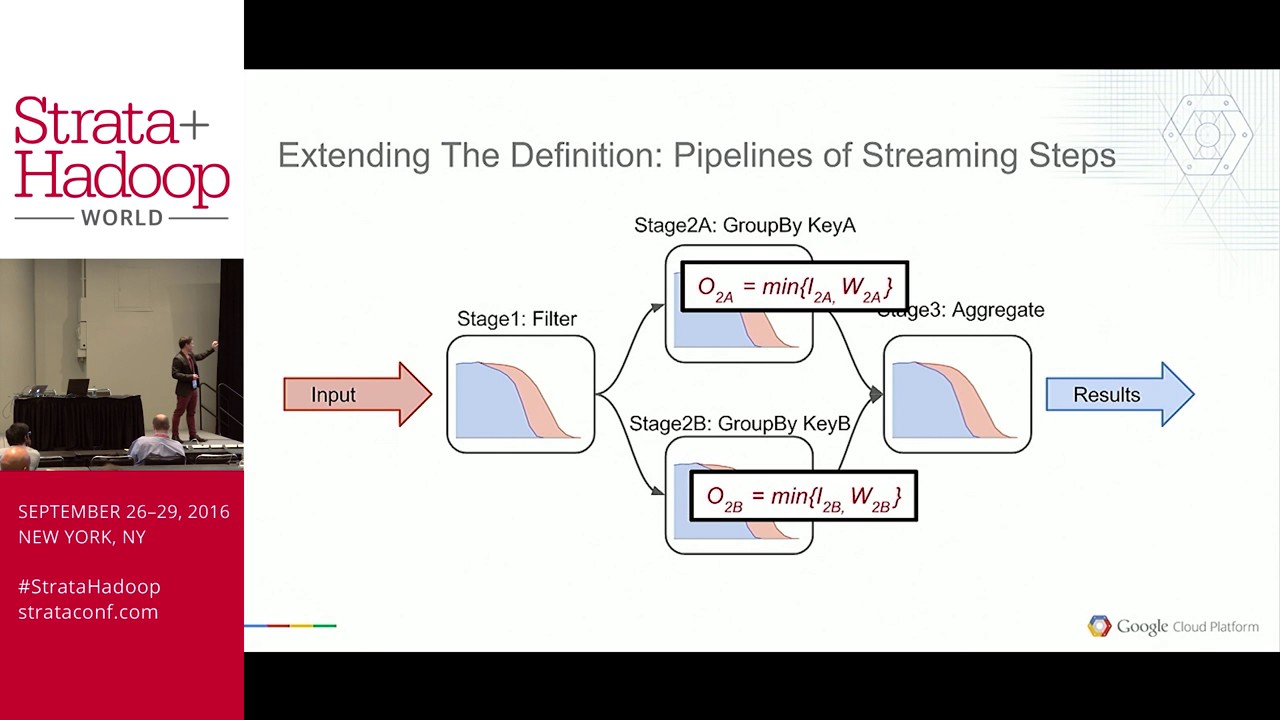
Two trends for data analysis are the ever increasing size of data sets and the drive for lower-latency results. In this talk, we present Apache Beam--a parallel programming model that allows one to implement batch and streaming data processing jobs that can run on a variety of scalable execution engines like Spark and Dataflow--and its new Python SDK. We discuss some of the interesting challenges in providing a Pythonic API and execution environment for distributed processing, and show how Beam allows the user to write a Python pipeline once that can run in both batch and streaming mode. We walk through a few examples of data processing pipelines in Beam for use cases such as real time data analytics and feature engineering with Tensorflow for machine learning pipelines.
Comments



![Streaming data processing pipelines with Apache Beam [in Python, naturally!] - PyCon APAC 2018](https://imager.clipsaver.ru/I1JUtoDHFcg/max.jpg)