OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod… скачать в хорошем качестве
OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod…
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod… в качестве 4k
У нас вы можете посмотреть бесплатно OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod… или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod… в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
OHBM 2022 | 178 | Talk | Catriona L Scrivener | Optimising analysis choices for multivariate decod…
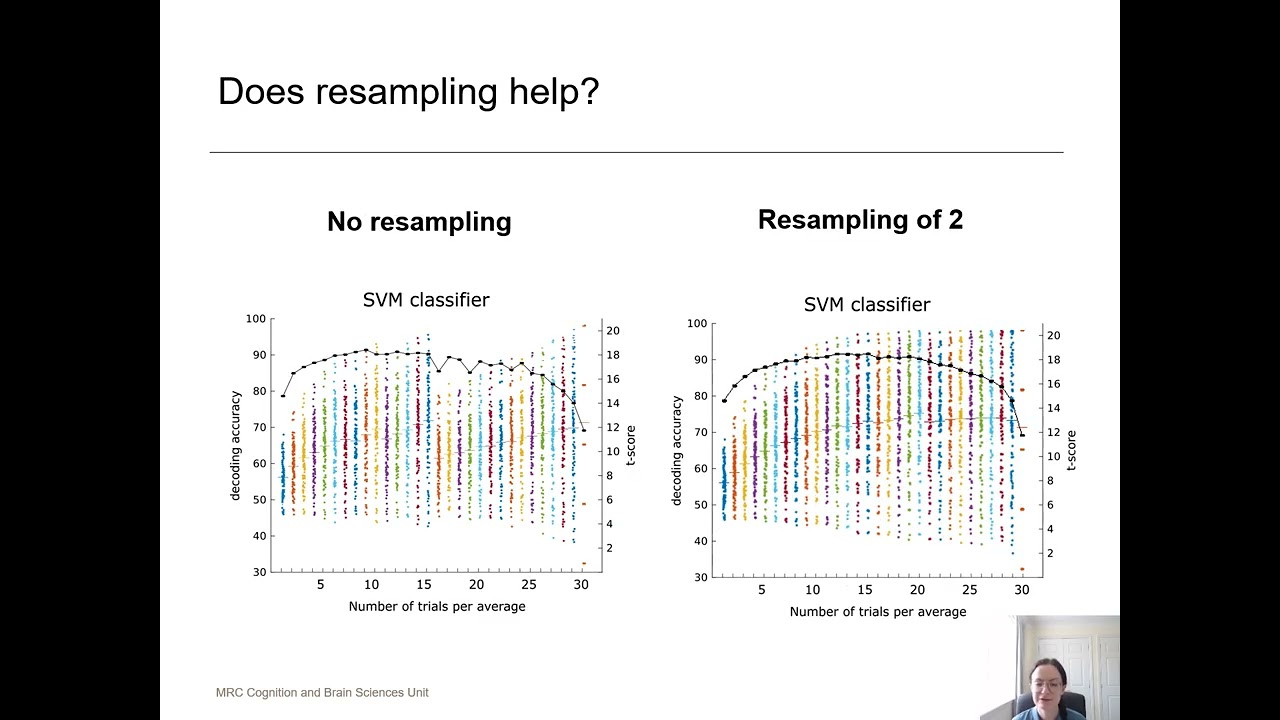
Title: Optimising analysis choices for multivariate decoding: creating pseudotrials using trial averaging. Session: Talk Speaker: Catriona L Scrivener Multivariate pattern analysis (MVPA) is a popular technique that can distinguish between condition-specific patterns of activation (Pereira, 2009). Applied to neuroimaging data, MVPA decoding reveals the evolution of information processing over time and/or space and is sensitive to information missed by univariate methods (Grootswagers, 2017; Haynes & Rees, 2006). However, several analysis choices influence decoding success, and the effects of these choices has not been formally evaluated. Previous results demonstrate that decoding accuracies can be higher when trials are averaged together before classification (i.e., creating ‘pseudotrials’), compared to single-trial decoding (Adam, 2020; Tuckute, 2019; Hebart & Baker, 2018; Grootswagers, 2017; Isik, 2014). However, this can increase between-subject variance which in turn affects the statistical outcome. There appears to be a trade-off between providing a classifier with fewer less noisy trials (more averaging) or a higher number of noisier trials (less averaging), and the optimal parameters may vary with choice of classifier and underlying effect size. In addition, we can create pseudotrials using random sampling with replacement (‘resampling’ the data) which increases the number of available samples, but also the dependence between them. The aim of the current work was to comprehensively assess the influence of these parameters using simulated data. We hope this will help researchers to determine the theoretically-optimal pseudotrial parameters for their analysis, thus reducing the empirical degrees of freedom and leading to more robust and replicable findings.
Comments




![[2025] Обратный проект нанофотонного цветового маршрутизатора, устойчивого к косому падению](https://imager.clipsaver.ru/j2Z1w5XtpQo/max.jpg)








![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)




![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)