Reinforcement Learning from Human Feedback (RLHF) Explained скачать в хорошем качестве
Reinforcement Learning from Human Feedback (RLHF) Explained
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Reinforcement Learning from Human Feedback (RLHF) Explained в качестве 4k
У нас вы можете посмотреть бесплатно Reinforcement Learning from Human Feedback (RLHF) Explained или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Reinforcement Learning from Human Feedback (RLHF) Explained в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Reinforcement Learning from Human Feedback (RLHF) Explained
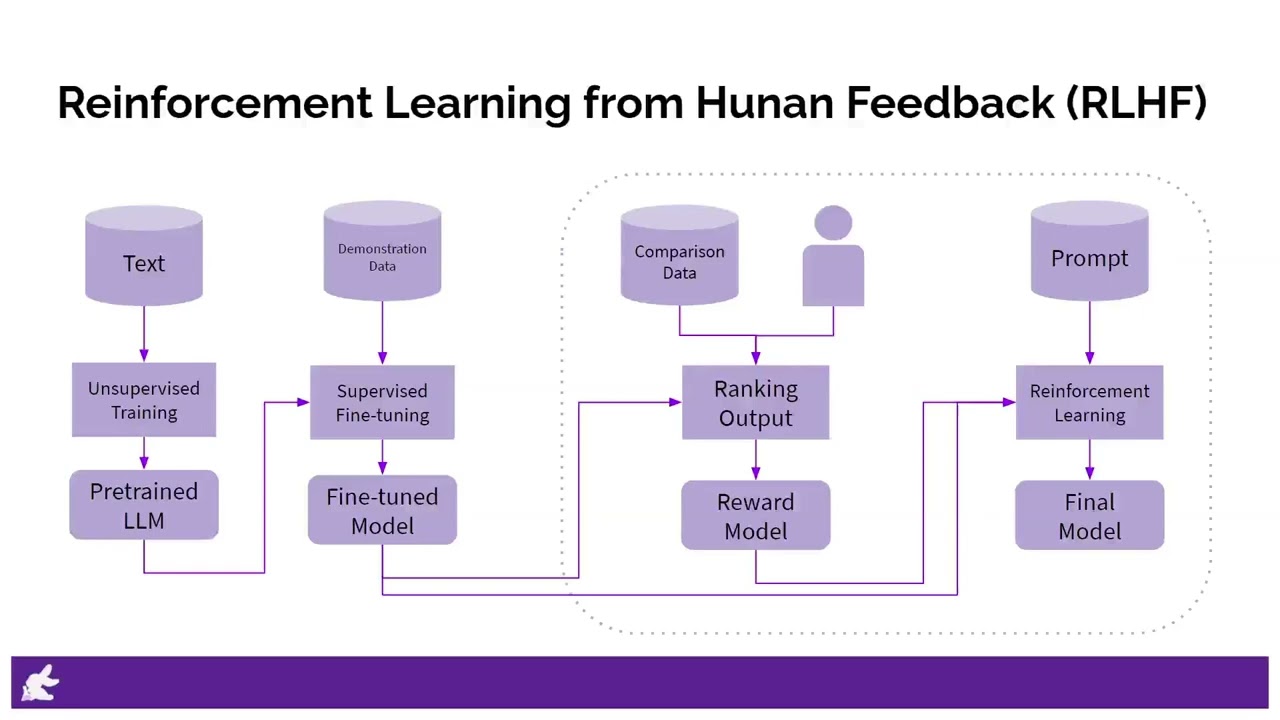
Bunny Labs is a division of Bunny Choo Choo, a NLP-based startup focused on education. We created this course to share the knowledge and experience we gained when building Bunny Choo Choo. We are exploring AI voice technology. Please like the video and subscribe us if you cannot distinguish whether the voice is from AI. Please comment if you know that this voice is generated by AI. IG: @bunny.choo.choo Pinterest: @bunnychoochoo Youtube: @bunnychoochoo Website: bunnychoochoo.com This video talks about Reinforcement Learning from Human Feedback (RLHF) method that we can fine-tuning LLM model effectively
Comments



















