ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM —Å–∫–∞—á–∞—Ç—å –≤ —Ö–æ—Ä–æ—à–µ–º –∫–∞—á–µ—Å—Ç–≤–µ
ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
–ù–µ —É–¥–∞–µ—Ç—Å—è –∑–∞–≥—Ä—É–∑–∏—Ç—å Youtube-–ø–ª–µ–µ—Ä. –ü—Ä–æ–≤–µ—Ä—å—Ç–µ –±–ª–æ–∫–∏—Ä–æ–≤–∫—É Youtube –≤ –≤–∞—à–µ–π —Å–µ—Ç–∏.
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...

–°–∫–∞—á–∞—Ç—å –≤–∏–¥–µ–æ —Å —é—Ç—É–± –ø–æ —Å—Å—ã–ª–∫–µ –∏–ª–∏ —Å–º–æ—Ç—Ä–µ—Ç—å –±–µ–∑ –±–ª–æ–∫–∏—Ä–æ–≤–æ–∫ –Ω–∞ —Å–∞–π—Ç–µ: ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM –≤ –∫–∞—á–µ—Å—Ç–≤–µ 4k
–£ –Ω–∞—Å –≤—ã –º–æ–∂–µ—Ç–µ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –±–µ—Å–ø–ª–∞—Ç–Ω–æ ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM –∏–ª–∏ —Å–∫–∞—á–∞—Ç—å –≤ –º–∞–∫—Å–∏–º–∞–ª—å–Ω–æ–º –¥–æ—Å—Ç—É–ø–Ω–æ–º –∫–∞—á–µ—Å—Ç–≤–µ, –≤–∏–¥–µ–æ –∫–æ—Ç–æ—Ä–æ–µ –±—ã–ª–æ –∑–∞–≥—Ä—É–∂–µ–Ω–æ –Ω–∞ —é—Ç—É–±. –î–ª—è –∑–∞–≥—Ä—É–∑–∫–∏ –≤—ã–±–µ—Ä–∏—Ç–µ –≤–∞—Ä–∏–∞–Ω—Ç –∏–∑ —Ñ–æ—Ä–º—ã –Ω–∏–∂–µ:
-
–ò–Ω—Ñ–æ—Ä–º–∞—Ü–∏—è –ø–æ –∑–∞–≥—Ä—É–∑–∫–µ:
–°–∫–∞—á–∞—Ç—å mp3 —Å —é—Ç—É–±–∞ –æ—Ç–¥–µ–ª—å–Ω—ã–º —Ñ–∞–π–ª–æ–º. –ë–µ—Å–ø–ª–∞—Ç–Ω—ã–π —Ä–∏–Ω–≥—Ç–æ–Ω ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM –≤ —Ñ–æ—Ä–º–∞—Ç–µ MP3:
–ï—Å–ª–∏ –∫–Ω–æ–ø–∫–∏ —Å–∫–∞—á–∏–≤–∞–Ω–∏—è –Ω–µ
–∑–∞–≥—Ä—É–∑–∏–ª–∏—Å—å
–ù–ê–ñ–ú–ò–¢–ï –ó–î–ï–°–¨ –∏–ª–∏ –æ–±–Ω–æ–≤–∏—Ç–µ —Å—Ç—Ä–∞–Ω–∏—Ü—É
–ï—Å–ª–∏ –≤–æ–∑–Ω–∏–∫–∞—é—Ç –ø—Ä–æ–±–ª–µ–º—ã —Å–æ —Å–∫–∞—á–∏–≤–∞–Ω–∏–µ–º –≤–∏–¥–µ–æ, –ø–æ–∂–∞–ª—É–π—Å—Ç–∞ –Ω–∞–ø–∏—à–∏—Ç–µ –≤ –ø–æ–¥–¥–µ—Ä–∂–∫—É –ø–æ –∞–¥—Ä–µ—Å—É –≤–Ω–∏–∑—É
—Å—Ç—Ä–∞–Ω–∏—Ü—ã.
–°–ø–∞—Å–∏–±–æ –∑–∞ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–µ—Ä–≤–∏—Å–∞ ClipSaver.ru
ORPO: –ù–û–í–´–ô –º–µ—Ç–æ–¥ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è DPO –∏ SFT –¥–ª—è LLM
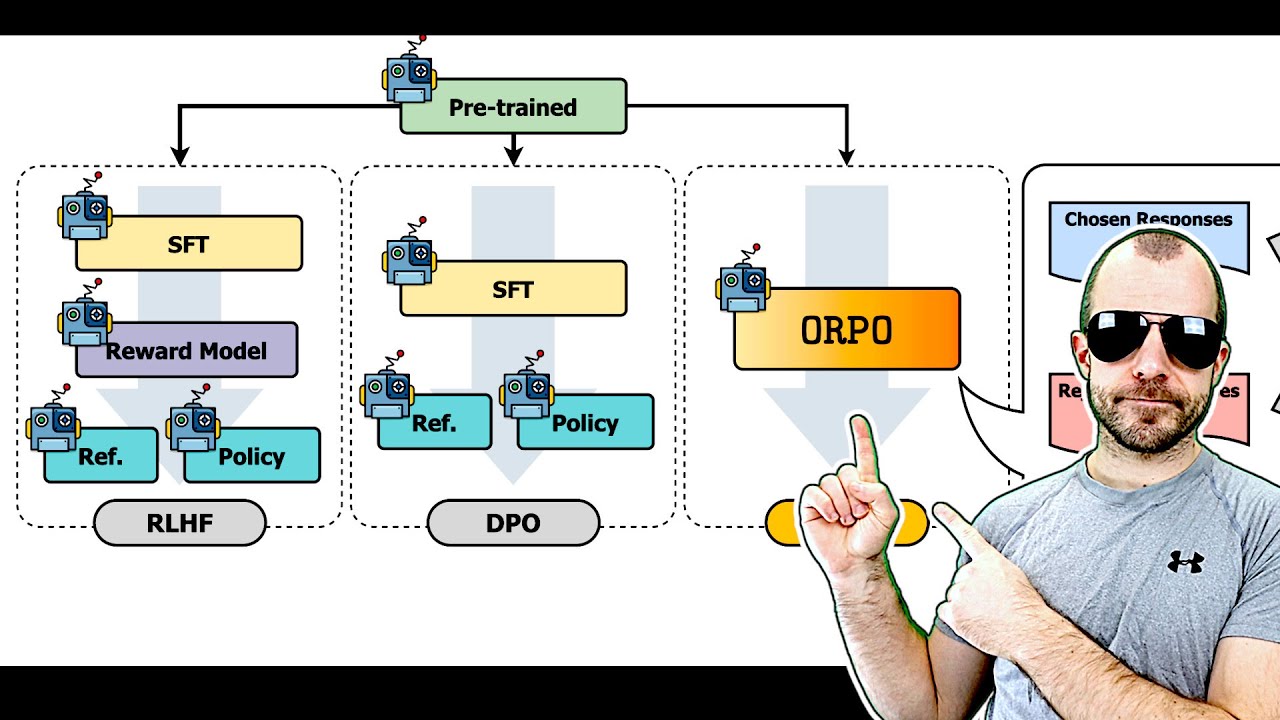
–í–º–µ—Å—Ç–æ –∫–ª–∞—Å—Å–∏—á–µ—Å–∫–æ–≥–æ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è SFT –∏ DPO –¥–ª—è –æ–±—É—á–µ–Ω–∏—è –Ω–∞—à–∏—Ö LLM –¥–æ—Å—Ç—É–ø–µ–Ω –Ω–æ–≤—ã–π –º–µ—Ç–æ–¥. –ò–Ω–Ω–æ–≤–∞—Ü–∏–æ–Ω–Ω—ã–π –º–æ–Ω–æ–ª–∏—Ç–Ω—ã–π –∞–ª–≥–æ—Ä–∏—Ç–º –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–∏ –æ—Ç–Ω–æ—à–µ–Ω–∏—è —à–∞–Ω—Å–æ–≤ ORPO, –Ω–µ —Ç—Ä–µ–±—É—é—â–∏–π —Ä–µ—Ñ–µ—Ä–µ–Ω—Ç–Ω–æ–π –º–æ–¥–µ–ª–∏, —É—Å—Ç—Ä–∞–Ω—è–µ—Ç –Ω–µ–æ–±—Ö–æ–¥–∏–º–æ—Å—Ç—å –≤ –¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω–æ–π —Ñ–∞–∑–µ –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏—è –ø—Ä–µ–¥–ø–æ—á—Ç–µ–Ω–∏–π. –ù–æ–≤—ã–π –º–µ—Ç–æ–¥ SFT —Å –≤—ã—Ä–∞–≤–Ω–∏–≤–∞–Ω–∏–µ–º –ø—Ä–µ–¥–ø–æ—á—Ç–µ–Ω–∏–π. –ú—ã —Ä–∞—Å—Å–º–∞—Ç—Ä–∏–≤–∞–µ–º —ç—Ç—É –∏–¥–µ—é —Å —Ç–æ—á–∫–∏ –∑—Ä–µ–Ω–∏—è —Ç–µ–æ—Ä–µ—Ç–∏—á–µ—Å–∫–æ–π —Ñ–∏–∑–∏–∫–∏ –∏ –æ—Ç–º–µ—á–∞–µ–º —Å—Ö–æ–¥—Å—Ç–≤–æ —Å –º–µ—Ç–æ–¥–æ–ª–æ–≥–∏—è–º–∏ —Ä–µ–≥—É–ª—è—Ä–∏–∑–∞—Ü–∏–æ–Ω–Ω—ã—Ö —á–ª–µ–Ω–æ–≤. –ú—ã —Ç–∞–∫–∂–µ –∏—Å—Å–ª–µ–¥—É–µ–º –∫–æ–Ω—Ü–µ–ø—Ç—É–∞–ª—å–Ω–æ–µ —Å—Ö–æ–¥—Å—Ç–≤–æ –º–µ–∂–¥—É –º–Ω–æ–∂–∏—Ç–µ–ª–µ–º –õ–∞–≥—Ä–∞–Ω–∂–∞ –∏ –Ω–æ–≤—ã–º–∏ –ø–æ–ø—Ä–∞–≤–æ—á–Ω—ã–º–∏ —á–ª–µ–Ω–∞–º–∏ –≤ –¥–æ–ø–æ–ª–Ω–µ–Ω–∏–µ –∫ –∫–ª–∞—Å—Å–∏—á–µ—Å–∫–æ–º—É —Ñ—É–Ω–∫—Ü–∏–æ–Ω–∞–ª—É –ø–æ—Ç–µ—Ä—å SFT. –ü–æ–∫–∞–∑–∞—Ç–µ–ª–∏ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç–∏ ORPO –ø—Ä–∏–≤–µ–¥–µ–Ω—ã –≤ —Å—Ä–∞–≤–Ω–µ–Ω–∏–∏ —Å –º–æ–¥–µ–ª—è–º–∏ LLama 2 –∏ Mistral 7B. ORPO: –ú–æ–Ω–æ–ª–∏—Ç–Ω–∞—è –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏—è –ø—Ä–µ–¥–ø–æ—á—Ç–µ–Ω–∏–π –±–µ–∑ —Ä–µ—Ñ–µ—Ä–µ–Ω—Ç–Ω–æ–π –º–æ–¥–µ–ª–∏ https://arxiv.org/pdf/2403.07691v2.pdf
Comments
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 11 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
11 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
-
 –¢—Ä–∞–Ω—Å–ª—è—Ü–∏—è –∑–∞–∫–æ–Ω—á–∏–ª–∞—Å—å 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
–¢—Ä–∞–Ω—Å–ª—è—Ü–∏—è –∑–∞–∫–æ–Ω—á–∏–ª–∞—Å—å 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 11 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
11 –º–µ—Å—è—Ü–µ–≤ –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 5 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
5 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
-
 14 —á–∞—Å–æ–≤ –Ω–∞–∑–∞–¥
14 —á–∞—Å–æ–≤ –Ω–∞–∑–∞–¥
-
 1 –≥–æ–¥ –Ω–∞–∑–∞–¥
1 –≥–æ–¥ –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 3 –¥–Ω—è –Ω–∞–∑–∞–¥
3 –¥–Ω—è –Ω–∞–∑–∞–¥
-
 1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
1 –¥–µ–Ω—å –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 9 –¥–Ω–µ–π –Ω–∞–∑–∞–¥
9 –¥–Ω–µ–π –Ω–∞–∑–∞–¥