[Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language скачать в хорошем качестве
[Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
![[Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language](https://imager.clipsaver.ru/Kgf7CigUfZc/max.jpg)
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: [Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language в качестве 4k
У нас вы можете посмотреть бесплатно [Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон [Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
[Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language
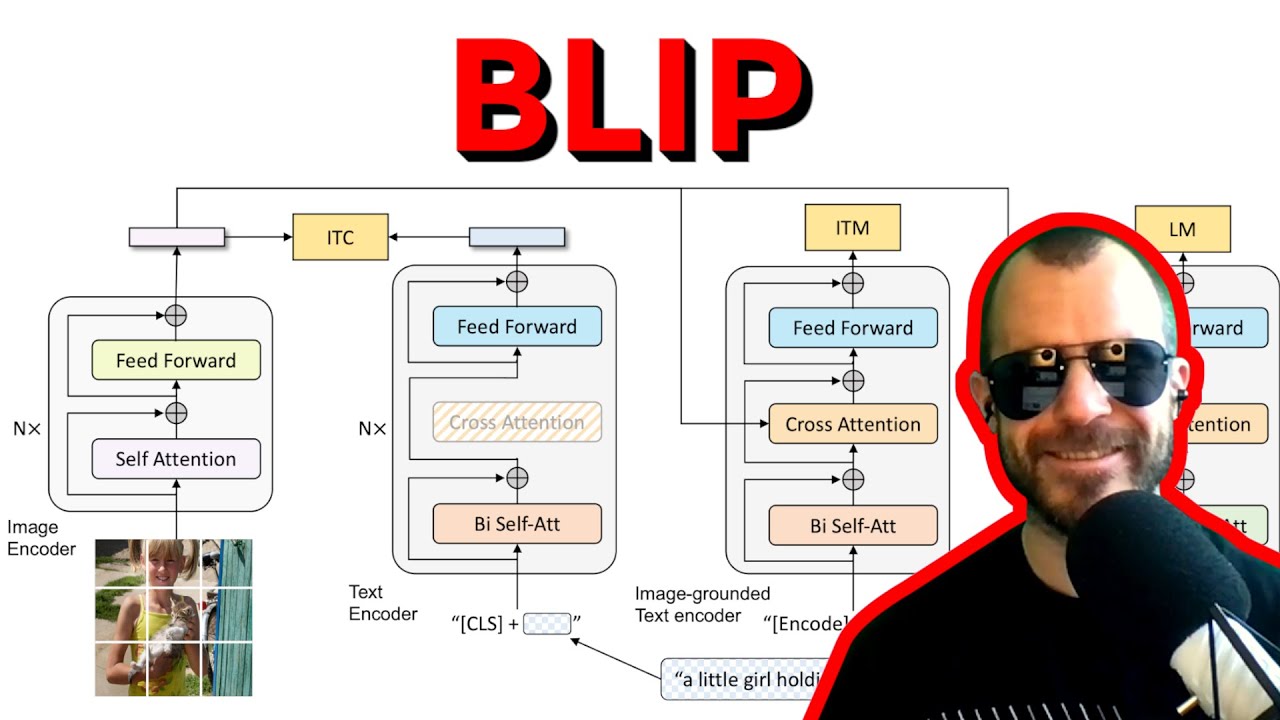
발표자: 고려대학교 DSBA 연구실 석사과정 마민정(minjeong_ma@korea.ac.kr) 1. 논문 제목 : BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML, 2022) 2. 원문 링크 : https://arxiv.org/abs/2201.12086 3. 요약 Vision-Language Understanding/Generation Task에 유연하게 적용할 수 있는 새로운 VLP 프레임워크인 BLIP 제안 Captioner가 Synthetic Caption을 생성하고 Filter가 노이즈 있는 캡션을 제거하는 Bootstrap 방식으로 노이즈가 있는 웹 데이터를 효과적으로 활용함 Image-Text Retrieval, Image Captioning, VQA 등 다양한 Vision-Language Task에서 SOTA 달성 Zero-shot 방식으로 Vision-Language Task에 직접 적용했을 때 강력한 일반화 능력을 보임 4. Keyword : #BLIP, #ALBEF, #VisionLanguage 5. 발표자료: http://dsba.korea.ac.kr/seminar/?uid=...
Comments
![[Paper Review] CentralityRank](https://imager.clipsaver.ru/MRkYhiN2NmY/max.jpg)
![반드시 기억하셔야 합니다, 왜냐구요? | 이선엽 AFW파트너스 대표 [긴급인터뷰]](https://imager.clipsaver.ru/6Re7yrTdzVI/max.jpg)

![[Paper Review] LLaVA: Large Language and Vision Assistant (Visual Instruction Tuning)](https://imager.clipsaver.ru/n58UZziEieo/max.jpg)
![[Paper Review] GraphRAG](https://imager.clipsaver.ru/mlsZIThxQcQ/max.jpg)


![[Paper Review] Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://imager.clipsaver.ru/JjxBNBzDbNk/max.jpg)


![[Paper Review] AI agent가 연구도 할 수 있을까?: The AI Scientist](https://imager.clipsaver.ru/OuvE7t3pmZ0/max.jpg)
![[DMQA Open Seminar] Transformer in Computer Vision](https://imager.clipsaver.ru/bgsYOGhpxDc/max.jpg)
![[Paper Review] Attention is All You Need (Transformer)](https://imager.clipsaver.ru/x_8cp4Vdnak/max.jpg)




![[Paper Review]Learning Transferable Visual Models From Natural Language Supervision | CoOp | Co-CoOp](https://imager.clipsaver.ru/ZXrU79CUej8/max.jpg)
