HNSW vs IVF indexing for vector databases | Principles and Architectures скачать в хорошем качестве
HNSW vs IVF indexing for vector databases | Principles and Architectures
3 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: HNSW vs IVF indexing for vector databases | Principles and Architectures в качестве 4k
У нас вы можете посмотреть бесплатно HNSW vs IVF indexing for vector databases | Principles and Architectures или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон HNSW vs IVF indexing for vector databases | Principles and Architectures в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
HNSW vs IVF indexing for vector databases | Principles and Architectures
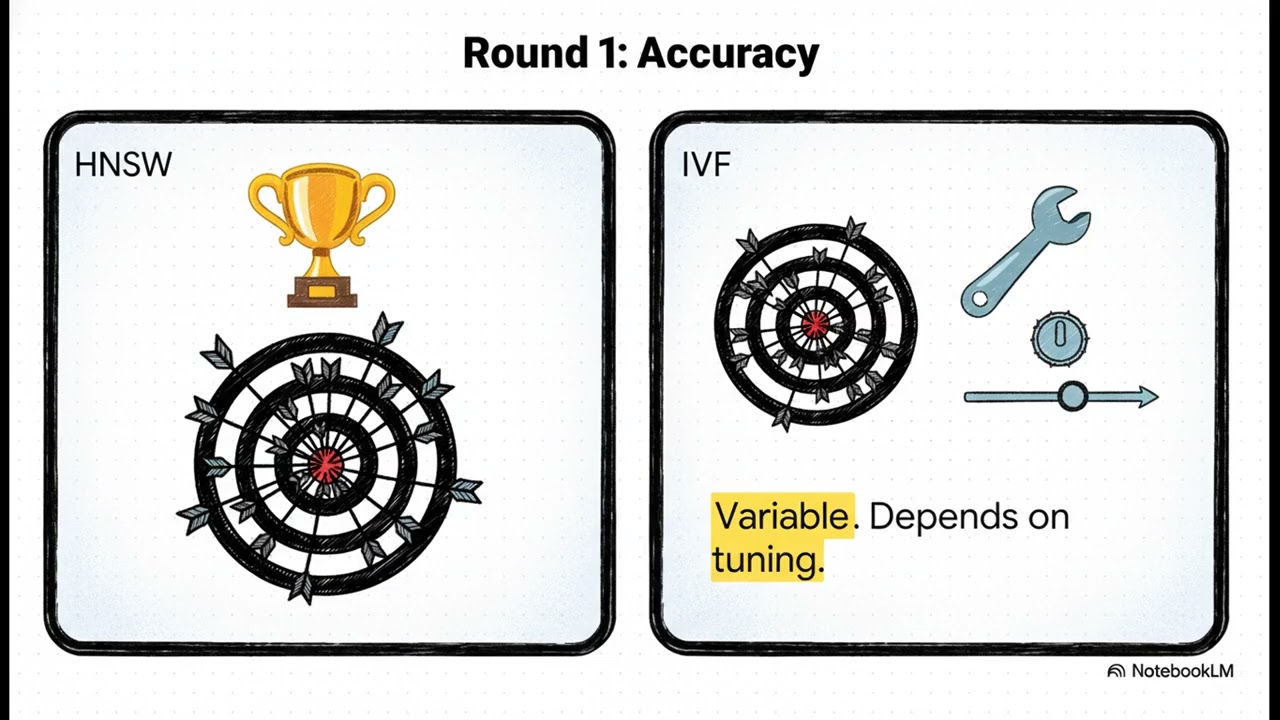
These sources examine the primary indexing strategies used in vector databases to facilitate efficient Approximate Nearest Neighbor searches. The documentation focuses on comparing HNSW, a high-precision graph-based approach ideal for memory-intensive and dynamic datasets, against IVF, a cluster-based method optimized for massive scales and limited hardware resources. Additional techniques like Product Quantization and Hashing are introduced as ways to further compress data and enhance retrieval speed. Each technical guide highlights the critical trade-offs between accuracy, memory consumption, and search latency. Ultimately, the literature suggests that selecting the right index depends on specific dataset sizes and hardware constraints, while noting a modern shift toward hybrid architectures that combine the strengths of both systems.
Comments

![Почему работает теория шести рукопожатий? [Veritasium]](https://imager.clipsaver.ru/ggI1xKzoANs/max.jpg)















![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)

