Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters скачать в хорошем качестве
Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters
8 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters в качестве 4k
У нас вы можете посмотреть бесплатно Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Beginner Intro to Neural Networks 10: Finding Linear Regression Parameters
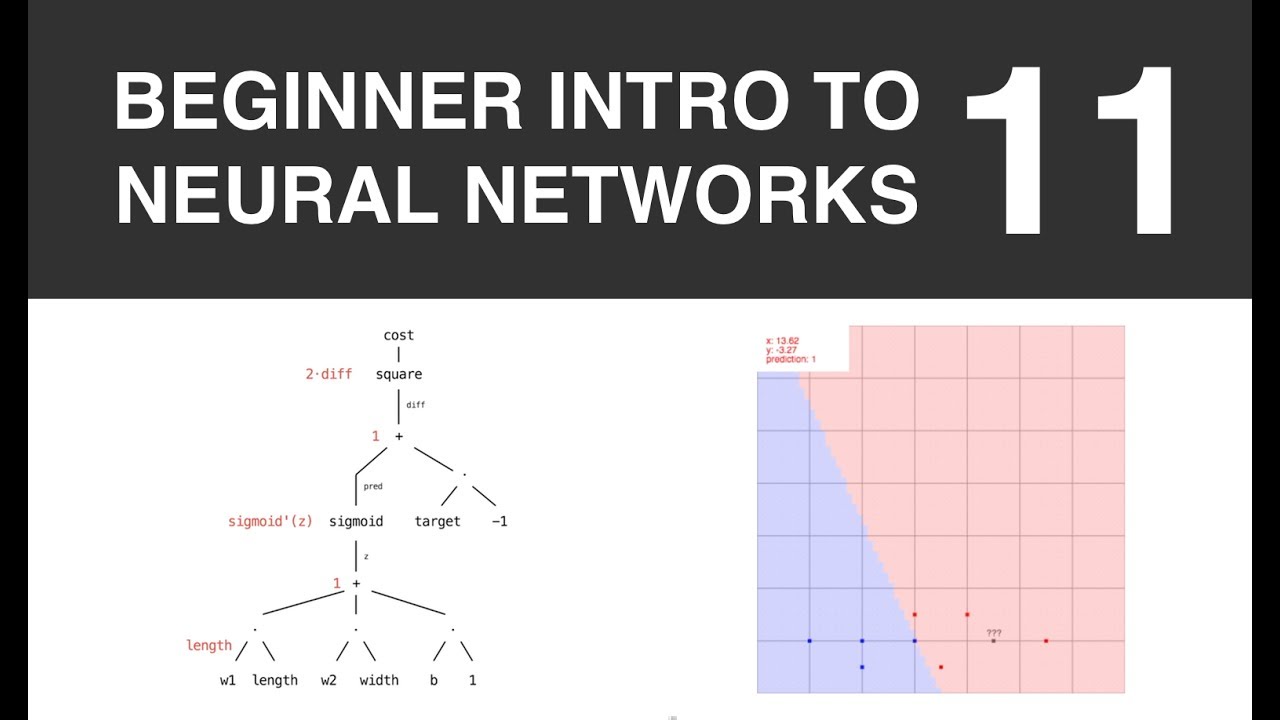
Hey everyone! In the last video we came up with this cost function: cost = (wags(1)-2)^2 + (wags(2)-4)^2 + (wags(4)-5)^2 It changes when we change w and b. In this video we'll see how to find the right changes to w and b to make it go down! Doing so will get us the best possible fit for our model and data. First let's expand the wags function in the cost function to see the entire thing: cost(w,b) = (1*w+b-2)^2 + (2*w+b-4)^2 + (4*w+b-5)^2 You can see that since our data is already all plugged in, we end up with a function that takes two inputs in, our model's parameters, and outputs a single number. Let's visualize our cost for different values of w and b! Since our function takes two inputs instead of 1, we can introduce another axis of our coordinate system to get a better visualization. We will make the x axis represent w, the z axis represent b, and the y axis represent the cost. Let's pick a random w and b to start with now, and plot it. It's sort of hard to tell with just a single point, so let's plot a whole grid of them! Let's try every pair of integer values for w and b. (grid of w and b pairs) And now we make their y axis the cost evaluated at whatever w and b coordiates they're at. (bowl) Now I'll connect each with a line just to make the visualiztion a bit more clear. Woah! Our cost looks like a bowl, and we want to get to the bottom of it! We need to find how to change w and b to get to the bottom of this bowl. This is where the partial derivatives come in. Here's the partial of the cost w.r.t. w, it's a function that takes where we currently are (w, b) and tells us how the cost changes for a small change in w. You can also think of it as the slope of the cost in the w dimension. dcdw(w,b)=... Here's the partial of the cost w.r.t. b, telling us how it changes for small changes in b: dcdb(w,b)=... I found these using rules from calculus (in particular the chain rule and power rule). But in practice you don't have to find these yourself (thankfully!). Many machine libraries like tensorflow, pytorch and theano will do it for you using something called automatic differentiation. We'll see more in later videos about how that works :-) We have our update now! We plug in w and b into these two functions, simplify, and their answers tell us how to change w and b to make the cost increase! Increase? Yes, so we actually have to subtract these numbers from w and b and the cost will then decrease. (apply update over and over) After a while our partial derivative functions approach zero, which is telling us we're either at a peak or basin of our surface... since remember, they're really functions that tell us the slope of the cost in the w and b dimensions, and when we're at a valley or peak the slope is zero! Since our partial derivative functions are close to zero and our updates are therefore really small, we've trained our model and gotten (approximately) the best fitting line! You can now use the model to make predictions! Plug in the w and b you found with your updates, then feed in new pats, simplify, simplify, and the number you get out is predicted wags for those pats! Be careful not to use inputs that are widely out of the range that you had used to train your model or you may get weird results (like negative wags (would growls count as negative wags?)), this is called extrapolation. There are many other things to be aware of as well when applying linear regression, so make sure you have a good understanding before applying it in real world situations. Things to be aware of are outliers, hidden variables, and not enough data to name a few. Also the model doesn't tell you that the pats CAUSED the wags.. It's merely a relationship between wags and pats. You could have trained the model to predict pats from wags instead!). In the next video I'll show you how do do all this stuff in python so you can experiment. Thanks for watching!
Comments













![Суть линейной алгебры: #13. Смена базиса [3Blue1Brown]](https://imager.clipsaver.ru/P2LTAUO1TdA/max.jpg)


