Agent Learns to do Reinforcement Learning скачать в хорошем качестве
Agent Learns to do Reinforcement Learning
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Agent Learns to do Reinforcement Learning в качестве 4k
У нас вы можете посмотреть бесплатно Agent Learns to do Reinforcement Learning или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Agent Learns to do Reinforcement Learning в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Agent Learns to do Reinforcement Learning
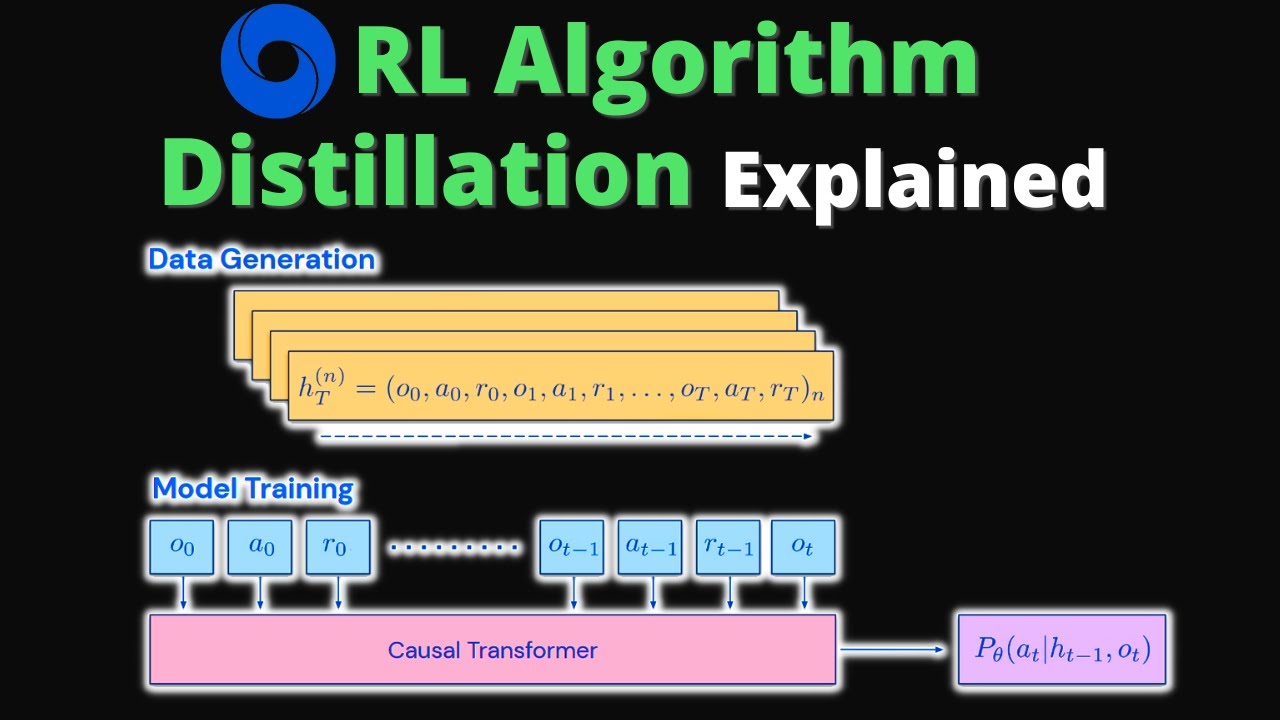
"In-context Reinforcement Learning with Algorithm Distillation" is a new paper from DeepMind about learning how to learn how to do Reinforcement Learning (RL) using behavior cloning over a learning history with a Transformer. The idea is simple, but I think the implications could be big for the future. Outline 0:00 - Intro 0:30 - Why I like this paper 2:08 - ClearML 3:17 - Algorithm Overview 7:50 - Bandits 9:06 - Robustness Results 15:08 - Speedup Results 22:00 - Other Results 23:00 - Conclusion ClearML - https://bit.ly/3GtCsj5 Social Media YouTube - / edanmeyer Twitter - / ejmejm1 RL AD Paper - https://arxiv.org/abs/2210.14215
Comments