Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE скачать в хорошем качестве
Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE
10 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE в качестве 4k
У нас вы можете посмотреть бесплатно Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Mixture of Experts, MoR and Self-Attention: Architectures of Efficiency. A comparative analysis. MoE
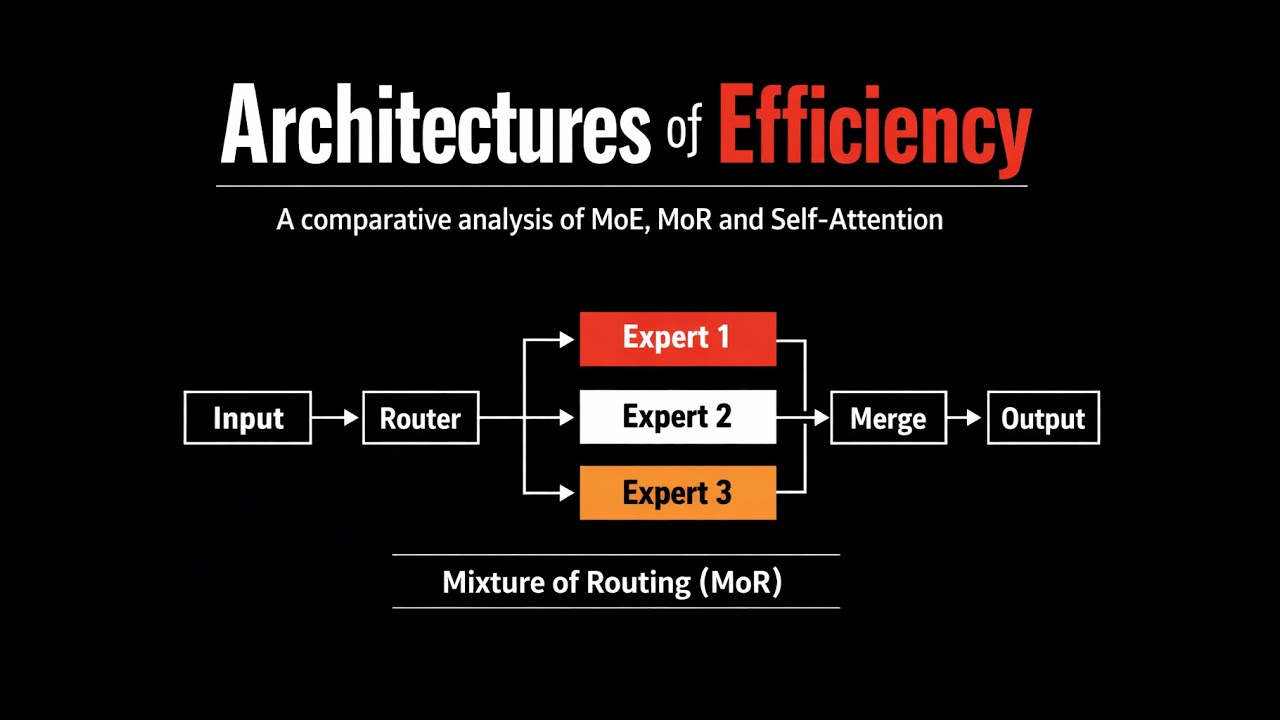
In the quest for more powerful AI, we’ve often followed a simple rule: deeper is better. We add more layers, more parameters, and more compute. But what if the secret to the next leap in intelligence isn't about how much we add, but how smartly we reuse what we already have? For years, Transformers have processed every token—whether it's a simple 'the' or a complex mathematical variable—with the exact same amount of computational effort. But not all tokens are created equal. Today, we’re breaking down Mixture-of-Recursions, or MoR, a framework that finally brings 'thinking on demand' to the Transformer. But it’s not just about the math; it’s about the hardware. We’re going deep on how this architecture solves the memory bottleneck with innovative KV caching strategies that maximize throughput and slash inference costs. If you’ve been following the rise of Mixture-of-Experts (MoE), this is the next logical step in the evolution of latent space reasoning.
Comments
![[Self-Attention] From Attention and SSL to the Era of GRPO. Generative AI Model Horizon.](https://imager.clipsaver.ru/WMz3UZipGWc/max.jpg)





![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)

![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)




![[Attention] Comparative Analysis of Self-Attention and Cross-Attention in Multi-Modal Architectures.](https://imager.clipsaver.ru/0wdl_5PKJ-g/max.jpg)




