FDPP: Fine-tune Diffusion Policy with Human Preference скачать в хорошем качестве
FDPP: Fine-tune Diffusion Policy with Human Preference
8 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: FDPP: Fine-tune Diffusion Policy with Human Preference в качестве 4k
У нас вы можете посмотреть бесплатно FDPP: Fine-tune Diffusion Policy with Human Preference или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон FDPP: Fine-tune Diffusion Policy with Human Preference в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
FDPP: Fine-tune Diffusion Policy with Human Preference
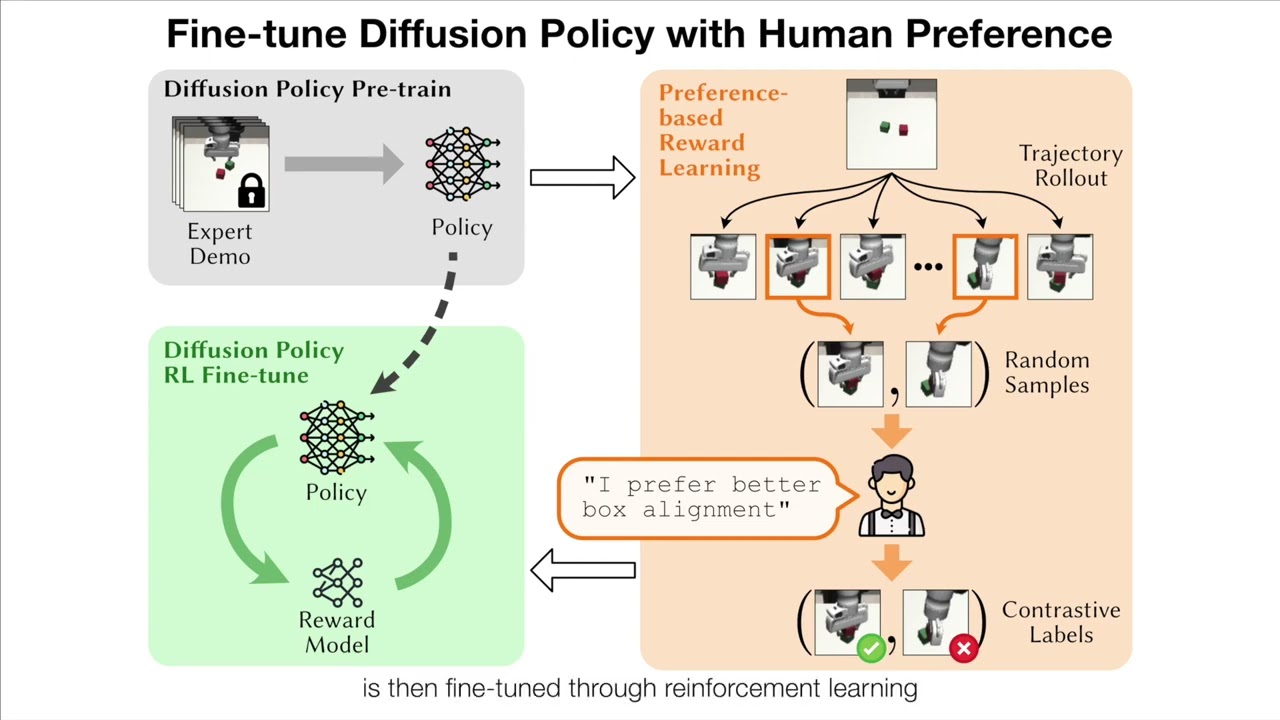
This is the supplementary video for the ICRA 25 publication on finetuning of diffusion policies using Reinforcement Learning (RL). An arXiv upload of the paper can be found here https://arxiv.org/pdf/2501.08259. Abstract : Imitation learning from human demonstrations enables robots to perform complex manipulation tasks and has recently witnessed huge success. However, these techniques often struggle to adapt behavior to new preferences or changes in the environment. To address these limitations, we propose Fine-tuning Diffusion Policy with Human Preference (FDPP). FDPP learns a reward function through preference-based learning. This reward is then used to fine-tune the pre-trained policy with reinforcement learning (RL), resulting in alignment of pre-trained policy with new human preferences while still solving the original task. Our experiments across various robotic tasks and preferences demonstrate that FDPP effectively customizes policy behavior without compromising performance. Additionally, we show that incorporating Kullback–Leibler (KL) regularization during fine-tuning prevents over-fitting and helps maintain the competencies of the initial policy.
Comments

![[ICRA25] Proactive Assistance in Human-Robot Collaboration through Task Progress Estimation](https://imager.clipsaver.ru/UyIJPxoL_KQ/max.jpg)






![[MERL Seminar Series Spring 2026] Is locomotion really that hard… and other musings on the virtues..](https://imager.clipsaver.ru/7WVmF7vomWM/max.jpg)




![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)
![Как сжимаются изображения? [46 МБ ↘↘ 4,07 МБ] JPEG в деталях](https://imager.clipsaver.ru/Kv1Hiv3ox8I/max.jpg)




